[ADP開発日誌 ]Ver 0.75 リリース バグフィックス
ブログの方ですが、一周年記念記事の追加やSQLのパフォーマンスの記事等ちょっととっちらかった感がありますが、ADPのVer 0.75をリリースします。基本的にバグフィックスになります。
・insert / update / delete でメモリリークのバグフィックス
・組込み述語(_table_quote)を削除し、組込み述語(_db_quote / _db_default_quote)を追加した。
SQLのパフォーマンスの記事のアップに際して環境を整えましたが、その際にデータのコピーをADPでやらせてみたところバグが発覚したので修正しました。
またSQLServerからMySQLにデータをコピーするに際してクオート文字の指定が_table_quoteだと不完全なので整理しました。
ちなみに、insertの性能ですが、悪いです。
MySQLやSQLServer2008以降では、多数の行をインサートするために、マルチプルインサート、Oracleではマルチテーブルインサートが使えるので、検討してみたい(専用の述語の追加になるか?)。
2011-09-13 | コメント:0件
[ADP開発日誌]0.74リリース マルチスレッド化の第一歩 & LLPlanets発表用リリース
ADP公開一周年記念記事がまだ途中ですが、 Ver0.74のリリースを行います。
Ver0.74は、Accessでの整数のインサート時のエラーの改修と、pipe述語の実装があります。
pipe述語というのは、以前話に出ました、マルチスレッド機能の1つでパイプライン処理を実現する述語になります。
ちなみに、本リリースにに基づき、LLPlanetsのライトニングトークで発表を行います。私を見かけた人は『ブログ見てます』と声を掛けていただければうれしかったりします。
では、pipe述語の使用例を見てみましょう。何回かやっていて最近ホットなSQLのパフォーマンスについての例になります。
関連記事1:[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
関連記事2:SQLの実行パフォーマンスについて 2010
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行(再掲)
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験1と同じです。
実行時間も同じで、約119秒です。
実験2 ADP側でjoin(ネステッドループ&キャッシュ)
続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験2-Bと同じコードになります。
実行時間ですが、約117秒となりました。実験1と比べて約1.6%程速くなっています。
実験3 ADP側でjoin(事前にマップ作成)
3つ目は、ADPでも事前にマップを作成し、joinを行うことができます。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験3と同じコードです。
実行時間ですが、約111秒で実験1より7%ほど速くなっていることが解ります。
続いて、pipe述語を使って並行処理をさせてみます。
実験1-P 素直にSQL側でjoinをさせたものをpipe実行
実験1のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).pipe.csv.prtn,next;
実験1のコードとの違いは4行目の,sql@($db,$str,[]).pipe.csv.prtn,next;
のpipeという記述で、これがpipe述語になります。pipe述語で区切られたコードは並行で処理を行います。
つまり
,sql@($db,$str,[])
の部分(バックトラックの実行)と
.csv.prtn,next;
の部分は並行で動作します。
sqlの部分は、.csv.prtn,nextの実行中にバックトラックを行います。
next述語で、pipeまで戻りますと、sqlの実行を待ち(同期)データを受け取ります。
ややこしいかも知れませんが、図で示すとよくわかるかと思います。
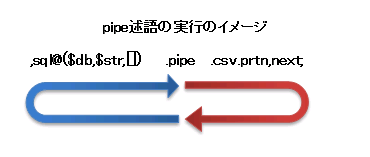
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。

比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験2-P ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行
続いて、実験2のコードにpipe述語を挿入しています。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
実行時間は、約89秒で実験2と比べて約24%速くなっています。
興味深いのは実験1-Pよりも速度向上が大きいです。pipe述語は半分に分割してそれぞれ実行するという方式をとっていますが、当然ですが常に半分になるとは限りません。上手く半分に分割できる場合もありますし、そうでない場合もあります。そのような関係でこのような逆転現象が発生します。一口にJOINのパフォーマンスといってもこのように様々な要因が絡んできますので、一概に『○○が効率的』といえないことを表す良い例となっています。
実験2-PP ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行2
実験2-Pのコードにさらにpipe述語を挿入しています。pipe述語は1つだけでなく複数入れることもできます。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,pipe ,csv($rec,$name).prtn,next;
実行時間は、約112秒で実験2-PPと比べて逆に遅くなっています。このように闇雲にマルチスレッドを行っても必ずしも速くならない場合がある(もちろん速くなる場合もある)のが面白いところです。pipe述語を2つ使うと3つスレッドが動作しますが、実験環境ではCPUコアが2つしかないので足の引っ張り合いのようなことになったようです。
実験3-P ADP側でjoin(事前にマップ作成)でpipe実行
続いて、実験3のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
実行時間は、約91秒で、実験3と比べて約18%速くなっています。
ちなみに実験3-Pからさらにpipeを挿入しても良いのですが、実験2-Pの時と同様にあまり速くならないので省略します。
結論
各実験結果を示します。
| 実験 | 実行時間(秒) |
|---|---|
| 実験1 | 119 |
| 実験2 | 117 |
| 実験3 | 111 |
| 実験1-P | 108 |
| 実験2-P | 89 |
| 実験2-PP | 112 |
| 実験3-P | 91 |
実験1~3どの場合でも、pipe述語が有効だということが分かります。これは、
・DBMSからデータを取得する
・ファイルへ書き出す
という2つのIO処理があり、pipe述語によって、それらを同時に実行することが出来る為です。
また実験2-PPと実験2-Pを比べても分かりますとおり闇雲にマルチスレッド化しても高速化が図れない場合もあります。
パフォーマンスアップは様々な要素が関わってきますので実験により確認しながらということが必要になります。
pipe述語はお手軽にマルチスレッドを実現でき、また取り外しも楽なので簡単に実験や試行錯誤が出来ます。
ADPのpipe述語はキャッシュ機能と同様に便利な道具として利用できるかと思います。
また、実験1-P、2-P、3-Pを比較しますとどれをとってもパフォーマンスにあまり差がないことがわかるでしょう。ADPの開発にあたりプログラマの自由度を高めるということも考慮しています。つまり、『○○でなければダメ』ではなく、どのアルゴリズムを採用するかはプログラマーの判断で、いか様にも選択できるような言語を目指しています。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
2011-08-19 | コメント:0件
[ADP開発日誌-公開1周年記念特集 Part6] プログラミング言語の制御構造のいろいろ(4)
ちょっと余計な記事が入りましたが、続きをC++の仮想関数の欠点
話が少し前後しますが、Part4の記事でC++の仮想関数呼び出しの仕組みについて説明しましが、ここではC++の仮想関数の欠点について指摘します。C++ではvtableというメンバ関数のアドレスを集めたテーブルを用いて仮想関数の呼び出しを実現していました。この方式は効率がよいのですが『コンパイル時に呼び出すべき仮想関数が決定しなければならない』という弱点があります。どういうことかといいますとC++でのメンバ関数呼び出し
object.virtual_method( arg1, arg2, arg3)
という呼び出しで、virtual_methodというメンバ関数名はコンパイル時に参照されますが、実行時には内部的に振られた番号(vtableのインデックス)になります。つまり実行時にはこの名前は参照できません。と同時にvtableのインデックスを取得する手段もないので、実行時に呼び出すメンバ関数を選択したいということができません。
これの何が欠点かピンとこないかもしれませんが、例えば、バッチファイルからVBScriptを使ってExcelを操ったりしますが、この特にExcelのバージョンをあまり気にせずにExcelを操作(メソッドを呼び出す)するでしょう。これと同じことは、C++の仮想関数の仕組みではストレートに実装できないということです。Windowsでは皆さんご存知のとおり、COMという仕組みをOSに実装することで実行時に呼び出すメソッドを特定することを行っています。
COMというとえらく古いと思われるかもしれませんが、.NET Framkework からExcelを呼び出す場合もCOM相互運用性という仕組みを使って.NET Framework → COM → Excel という風に呼び出しいます。
話が脱線しますが、私は.NET Frameworkが廃れるのではないか? と思っていますが、その理由のひとつが .NET FrameworkがCOMやOLE DB等のようにWindows APIを充分に置き換えていないと思えるところにあります(もっとも先のことは解りませんのでなんともいえませんが)。
関数の動的なロード&実行の例
場合によって呼び出す関数を変えるというプログラミングテクニックは、オブジェクト指向プログラミング以外にもあります。典型的な例のひとつにデバイスドライバがあります。
デバイスドライバはご存知のとおりハードウェアとOSのAPIを橋渡しするソフトウェアでハードウェアに合わせて作成されています。ハードウェアを変えるとそれにあわせてデバイスドライバも変えます。
デバイスドライバはCで記述されることが多いです。最近のOSではPlag&Playが一般的になりましたし、USB接続機器ではOSを再起動せずに、デバイスドライバがロードされます。このような動的なソフトウェアのロードの仕組みはどうなっているのでしょうか?
続いては、公開1周年記念特集記事として『プログラミング言語の制御構造のいろいろ(5)』を書いてみます。
2011-08-14 | コメント:0件
[ADP開発日誌-公開1周年記念特集 Part5] プログラミング言語の制御構造のいろいろ(3)
Part3の記事が短く、Part4(前回の記事)が長かったりバランスが悪いですが、まぁBlogということでご容赦を。メンバ関数呼び出し(thiscall)の補足
前回の記事にありましたメンバ関数の呼び出し規約(thiscall)について少し補足しますと、この呼び出し方法は一部のコンパイルで採用されているもので全てのコンパイラに当てはまりません。ちなみにVisual Studio 2008のC++コンパイラも違うやり方を採用しており、thisポインタをスタックに積むのではなくECXレジスタに代入します。thisポインタをECXに保存するとメンバ変数にアクセスする際に高速に処理が行えるのでこの方が効率的かと思います。思い出話をしますと、Visual Stduioの昔のバージョンでは、thisポインタはスタックに積まれていたと記憶しています。ADPの高速化に際してアセンブラコードを読んでいて『なんか変だな・・・』という感じで調べるとVisual Stduio 2008ではこのようになっていると気づきました。
仮想関数とif文
前回の記事に「仮想関数の説明はしない」と書きましたが、よくよく考えると仮想関数の仕組み(というか利用方法)を書かないと言いたいことが言えないことに気づきましたので書きます。仮想関数の有効性を示す例を示します。
以下、C/C++の擬似コードになります。if文を用いてデータタイプを判定しデータタイプに応じた変換を行い、valueの内容を文字列に変換しています。
char buf[512];
if ( value_type == int ) {
sprintf( buf, "%d", value);
} else if ( value_type == double ) {
sprintf( buf, "%f", value);
} else if ( value_type == char* ) {
strcpy( buf, value);
}
ここで、個別の変換処理(sprintfやらstrcpy)を仮想関数に置き換えます。
virtual int::to_string(char *buf) {
sprintf( buf, "%d", value);
}
virtual double::to_string(char *buf) {
sprintf( buf, "%f", value);
}
virtual char*::to_string(char *buf) {
strcpy( buf, value);
}
呼び出し部分のコードは、以下のとおりになります。
char buf[512]; value.to_string(buf);
仮想関数とはデータのタイプに合わせて実際のメンバ関数が呼び出される言語の機能になります。ここで、to_stringが仮想関数になり、実際に呼び出されるメンバ関数は、valueのデータタイプ(intやらchar*)に合わせて呼び出されることになります。ちなみにC++ではintやdoubleはクラスではないのでこのような仮想関数を作成することは出来ませんのであくまでも例になります。
仮想関数ですが、一見ややこしいですが、『データタイプに合わせて処理を行う』ような場合にはほぼ問題なく仮想関数に変換できるかと思います。ADPはC++で作成していますが、多くの場面で仮想関数を使っています。
例ではかなり端折っているので便利さが伝わりにくいですが、仮想関数を用いるとswitch文が減る(switch文もif文の一種と考えられる)といわれているとおり、今までif文が連なっていたコードが
value.to_string
とすっきりと記述出来るようになっています。重要な点はif文で書かれたコードブロックが to_string に置き換わり抽象度が上っていることです。抽象度が上がることが必ずしも可読性が増すわけではないですが、仮想関数を用いると呼び出し側のコードがすっきりとすることは分かるかと思います。
本記事のテーマである制御構造のいろいろという観点でみますと、仮想関数とはif文と関数呼び出しが混ざったものとも理解できます。
ちなみに、オブジェクト指向というとどうしても大きな括り(動物クラスとか社員クラスとか)の話になりますが、int型とかdouble型のような基本的な型でも行うことが出来、結構便利だったりします。C++では、intやdoube型ではメンバ関数を作ることが出来ませんが、Rubyのように使える言語もありますので試す価値はあります。またADPも同様なコードを記述することができます。
ADPのユニフィケーション(パターンマッチング)
前節で、仮想関数はif文と関数が混ざったものと説明しましたが、ADPでは関数呼び出し(述語の評価)に際しては、まずユニフィケーションが行われます。これは仮想関数を一般化しより強力かつ柔軟に呼び出すべき関数を選定できると考えることも出来ます。ユニフィケーションについては、こちらを参照下さい。
続いては、公開1周年記念特集記事として『プログラミング言語の制御構造のいろいろ(4)』を書いてみます。
2011-08-08 | コメント:0件
[ADP開発日誌-公開1周年記念特集 Part4] プログラミング言語の制御構造のいろいろ(2)
前回からちょっと間が空いてしまいましたが、ADPの1周年記念記事のPart4です。関数呼び出しのスタックの使われ方
前回の記事の終わりにスタックという言葉が出てきましたが、スタックとはプロセス(正確にはスレッド)毎に用意されているメモリエリアで、関数呼び出しやローカル変数の保持に使われます。
以下のC言語での関数呼び出し時のスタックの使われ方の例を図1に示します。
func( arg1, arg2, arg3); /* ------- ※1 */
図1
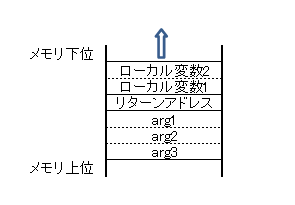
スタックは伝統的にアドレスの上位(数字が大きい)から下位に向かって領域が確保されます。
※1の関数が呼び出されるとき、先ず引数がスタックに積まれ、次いでリターンアドレス、そしてローカル変数の領域が確保されます。関数というのはどこから呼び出されても元の場所に戻ることが出来ますが、それが実現できるのは、呼び出し後に実行すべき命令のアドレス(リターンアドレス)をスタックに保持しているからです。
また、同時にどこから呼び出されてもローカル変数が『関数内で一時的に有効な変数』として機能できるのもスタックに変数のエリアを確保しているからになります。
ちなみに、数年前に流行したセキュリティリスクでバッファオーバーランというものがありますが、これはローカル変数の領域を溢れさせアドレスの上位にある戻りアドレスを書き換えてウイルスのプログラムを実行しようというC言語の関数呼び出しの仕組みを悪用したものになります。現在ではCPUレベルでの対策(NXビットとかXDビットとか呼ばれものでデータ領域の実行の禁止)が行われ、バッファオーバーランの脆弱性が起こりにくくなっています。
スタックには引数が積まれていますが、引数が積まれる順番には2通りのやり方があります。図1ではリターンアドレスに次いで arg1,arg2,arg3 と積まれていますが、反対に arg3,arg2,arg1 というやり方もあります。arg3,arg2,arg1の順番ですが、一見すると反対に見えますが、スタックに積む順番はarg1,arg2,arg3となります。ややこしいですが、※1の擬似アセンブラコードを示すと意味が良く分かるかと思います。
※2 ※1の擬似アセンブラコード(cdecl呼び出し) PUSH arg3 PUSH arg2 PUSH arg1 CALL func
PUSH命令の発行順とスタック上のリターンアドレスから見た順番が反対になります。
関数の呼び出し方法(つまりどのように機械語に翻訳するか)を呼び出し規約(主にx86のCPUで用いられている表現)といい、※2のような呼び出し方法をcdeclと呼びます。呼び出し規約はその他にPASCAL(文字通りPASCALで採用されている)とかstdcall(Windows-APIで採用)とかthiscall(C++のメンバ関数呼び出し)等があります。
メンバ関数の呼び出しでのスタックの使われ方
続いて、C++のメンバ関数呼び出しでのスタックの使われ方について説明します。
以下のC++でのメンバ関数の呼び出し時のスタックの使われ方の例を図2に示します。
object.method( arg1, arg2, arg3); // ------- ※3
図2
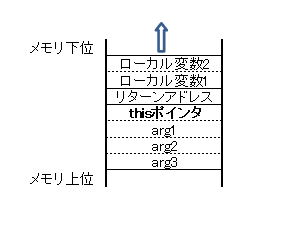
※3の擬似アセンブラコードを以下に示します。
※4 ※3の擬似アセンブラコード(thiscall呼び出し) PUSH arg3 PUSH arg2 PUSH arg1 PUSH object CALL method
違いは、object(正確にはobjectのアドレス)がthisポインタとして引数の一つとしてスタックに積まれていることです。その他の違いはありません。こうしてみるとオブジェクト指向というのは単純に
method( &object, arg1, arg2, arg3)
というコードを、
object.method( arg1, arg2, arg3)
という風に記述できる構文上の違いであるに過ぎないということに気づくかと思います。
ADPでは、この考え方を推し進めて、メソッド形式(メンバ関数呼び出しとほぼ同じ意味)として通常の述語形式での呼び出しとメソッドの呼び出しを混ぜて使うことができるようにしています。
ちなみに、私も含めて、多くのC言語の上級エンジニアがこのような見方をしてC言語からC++(オブジェクト指向)に移行していたかと思います。
もっとも、この話は、『仮想関数はどのように機械語に翻訳されるのか?』の話をしなければ終わりになりません。
次いで、仮想関数の呼び出しの話をします。
仮想関数の呼び出しでのスタックの使われ方
前節で説明したメンバ関数の呼び出しは従来の関数呼び出しの延長線上のものですが、ここでは、仮想関数と呼ばれるオブジェクト指向独特の呼び出し方法について説明します。以下の仮想関数の呼び出しについて考えます。ちなみにスタックの構成は図2で仮想関数・通常のメンバ関数(非仮想関数)での違いはありません。
object.virtual_method( arg1, arg2, arg3); // ------- ※5※5の擬似C++コードを以下に示します。
※6 ※5の擬似アセンブラコード(thiscall呼び出し) PUSH arg3 PUSH arg2 PUSH arg1 PUSH object MOV EAX, [object + vptr] ; ------------------- A MOV EDX, [EAX + virtual_method_offset] ; ----- B CALL EDX ; ------------------------------------ C
object + vptrなどや、EAX + virtual_method_number の部分がかなり曖昧ですが、エッセンスとして読んでいただければと思います。
※6のアセンブラコードではよく分からないかと思いますので、まずはオブジェクトのメモリレイアウトを図3に示します。
図3
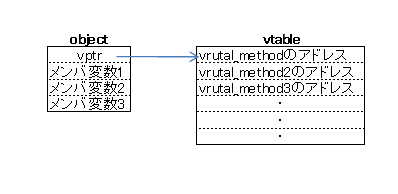
vtableと呼ばれるテーブルに呼び出すべき仮想関数の場所(アドレス)が格納されています。
また各objectはvtableの場所(アドレス)を保持する変数(ポインタ)を持っています。
さらに、機械語の特徴のとして関数呼び出し(CALL命令)は、常に同じ場所(アドレス)の関数を呼び出すだけでなく、変数(レジスタ)を通して間接的に呼び出すこともできるようになっています。
以上を踏まえて再度、擬似アセンブラコードを説明しますと、
Aでは、vtableを参照しています。EAXとはレジスタというCPUが持っている変数になりますがそこへvtableのアドレス(vptr)を代入しています。[] というのはアセンブラでのポインタ参照(間接演算子 *)になります。
Bでは、virtual_methodの呼び出すべきアドレスを、EDXに代入します。このvirtual_method_offsetですが配列のインデックスのようなもので、図3では0ということになります。
最後のCのCALL命令が、A,Bを通して取得した呼び出すべき仮想関数の呼び出しを行っていることになります。
このように擬似アセンブラコードを通してみますと、説明は難しいですが、たったの2命令の追加で仮想関数呼び出しを実現しており、C++での仮想関数呼び出しというのはかなり効率的であることが分かります。
もともと、私はアセンブラが大好き(ハードウェアを直接制御できるので)だったのですが、時代に押されてC言語を使うようになりましたが、その理由の一つとしてC言語が高級アセンブラとして設計された(つまりこのように簡単にアセンブラに置き換えられる)から動作がよく理解しやすい面があったからで、その設計思想はC++にも引き継がれていることが分かります。
続いては、公開1周年記念特集記事として『プログラミング言語の制御構造のいろいろ(3)』を書いてみます。
2011-08-04 | コメント:0件