llama.cppの開発&最適化、環境構築
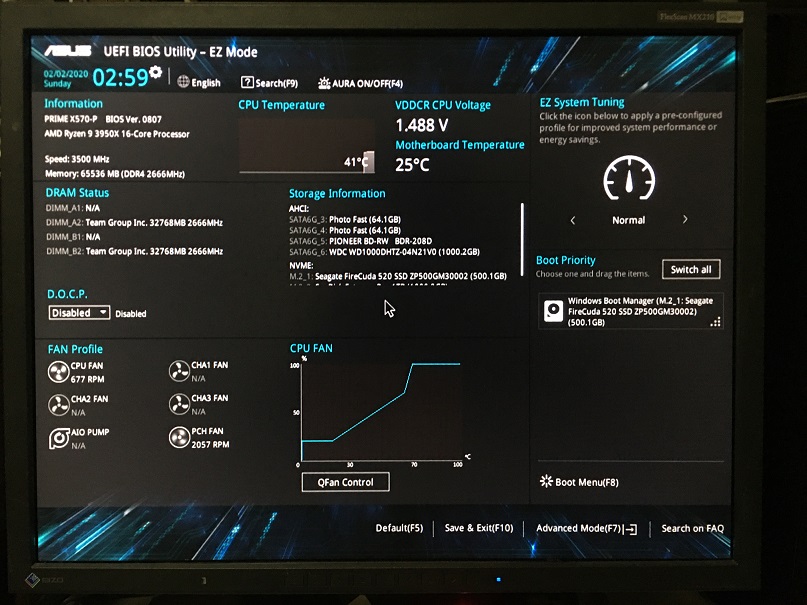
私のAI体験、2026年2月の活動、ということで、我がAIマシン(Core i9-10980XE,メモリ256GB+GeForce GTX1080Ti、GeForce RTX3070)にllama.cppの環境構築を行ったので、そのメモになります。
(事前セットアップ)
- OSのセットアップ、各種ドライバーをインストール
- Cuda toolkitをインストール
インストールされているグラフィックボードのバージョンに合ったバージョンをインストールする。
例)GeForce GTX1080Ti用のCuda toolkitは、12.8.0になる。 - Visual Studioをインストール
Visual Studio 2022 community Editionをインストール - Gitもインストールしておく
llama.cppをダウンロード&ビルド
下記作業をVisual studioのDeveloper Command Prompt for VS2022で行う
- https://github.com/ggml-org/llama.cppのページにあるQuick startのBuild from source by cloning this repository - check out our build guideを参照
- ダウンロードは
git clone https://github.com/ggml-org/llama.cpp cd llama.cpp
で行う。 - ビルドのコンフィグレーションを行う
cmake -B build -DGGML_CUDA=ON -DCMAKE_CXX_FLAGS="/utf-8 /EHsc" -DCMAKE_C_FLAGS="/utf-8" -DLLAMA_BUILD_BORINGSSL=ON -DCMAKE_CUDA_ARCHITECTURES="61;86"
最後の、DCMAKE_CUDA_ARCHITECTURESの61が1080Ti、86が3070用の設定になる。 - ビルドを行う
cmake --build build --config Release -j %NUMBER_OF_PROCESSORS% - コードページに関するワーニングがでるが無視しても動作した。一部のツールは文字化けするかもしれません。
動作確認
- llama-serverの実行
llama-server -hf unsloth/Qwen3-VL-235B-A22B-Thinking-GGUF:Q5_K_M -ngl 0 -b 512 --flash-attn on --host 0.0.0.0 --port 8080
ファイアーオールが警告が出たらポートを解放する - クライアントからアクセス
http://(llamaのマシンのIP):8080/でアクセス
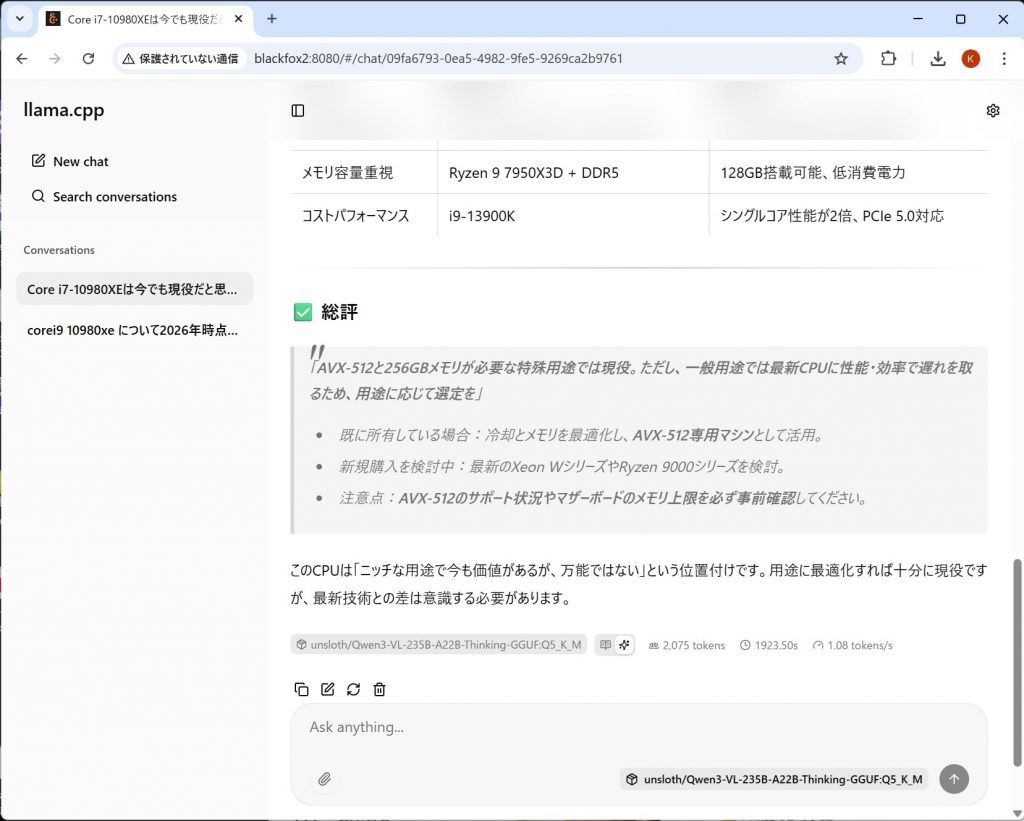
モデルがQwen3-VL-235B-A22B-Thinking-GGUF:Q5_K_Mで、だいたい、1~2Token/sec、つまり1秒に1文字出力される。何かすると20分ぐらいかかるので、これを高速化できればうれしいという話。
Visual Studioからの起動&コンパイル
- llama.cppをダウンロードした場所にbuildフォルダが作成される。このフォルダをカレントディレクトリとしてVisual Studio(devenv.exe)を起動する。
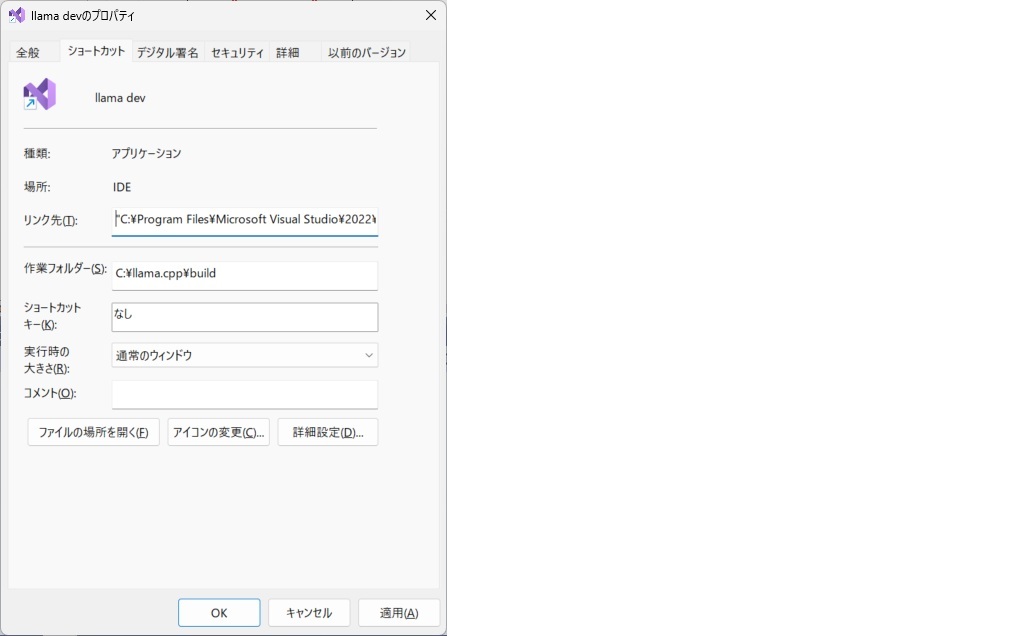
下記の要領でショートカットを作っておくと良い
リンク先:"C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\IDE\devenv.exe" llama.cpp.sln (デフォルトインストール)
作業フォルダ:C:\llama.cpp\build (llama.cppをc:\llama.cppにダウンロードしたと仮定)
「詳細設定ボタン」→「管理者として実行」にチェックを入れる(プロファイル時に必要)。
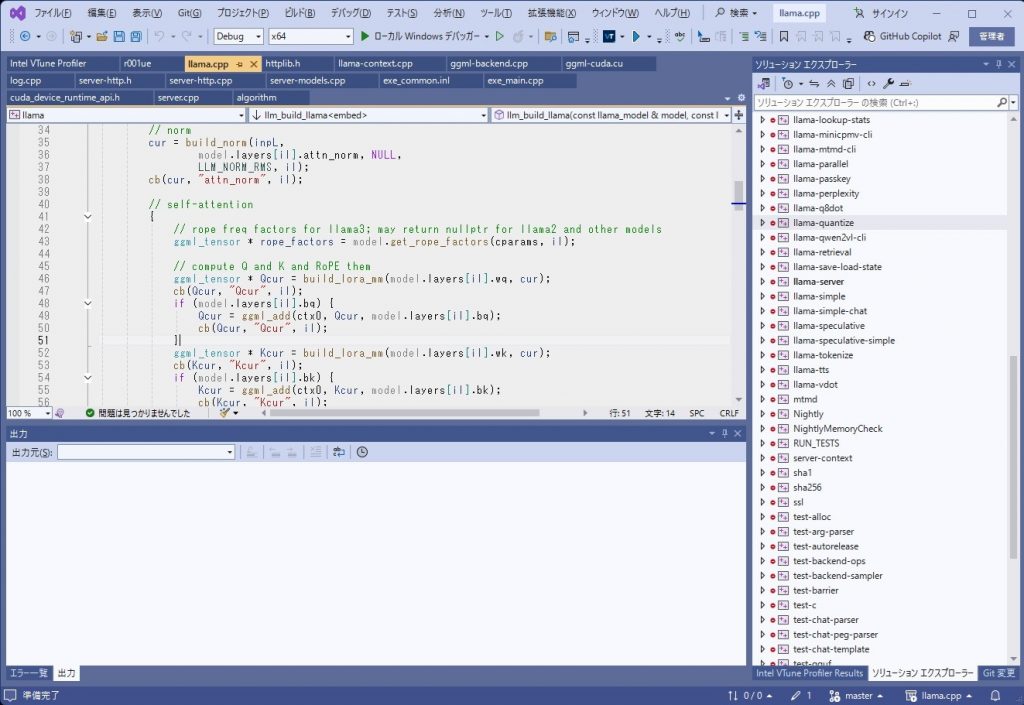
- デバックモードとリーリースモードで、リコンパイルを行ってみる。
VTuneのインストール&動作確認
- VTuneをインストール
使っているCPUに対応したバージョンのVTuneをインストールする。 - VTuneは、最新バージョンしかダウンロードできない。2026年2月現在の最新バージョン2025.8.1.7では、Ice Lake以降のCPUしか対応していない。Core i9-10980XEは、Cascade lake(1世代前)なので対応していない。ので、事前にダウンロードしているもの(2023)を利用する。
- 2022では、Windows11 25H2の環境ではインストールに失敗した(厳密にいうと2024のインストール&アンインストール後に行ったのでそのせいでインストールに失敗した可能性もある)。
- 2024では、正常にプロファイルが取れなかった。
- インストール時のオプションで、Visual Studioのツールにチェックが入っていることを確認すること。
- 先に2024をインストールするとアンインストールしても一部ファイルが残っており、2023をインストールしてもショートカットが2024側を指すので起動しない。
C:\Program Files (x86)\Intel\oneAPI\vtune
以下のフォルダをチェックすること。 - 出来れば、古いバージョンから試して不用意にバージョンをあげない方がよい。
- VTuneの起動
インストールが終了すると、Visual Studioのメニューにアイコンがでるのでプロファイルを行える。 - ソースコードを見るには、プロジェクトの設定でデバッグ情報を出力するようにすれば良いが、デバッグモードで行った方が面倒が少ない。この場合、コードが最適かされないのでパフォーマンスが下がるが、概ね、半分ぐらいの速度になる。あまり遅くなっていない。そもそも手動で最適化を行うのでコンパイラの最適化は止めても大丈夫かと思う。手動の最適化が終わった後に最終的にONにすればよい。
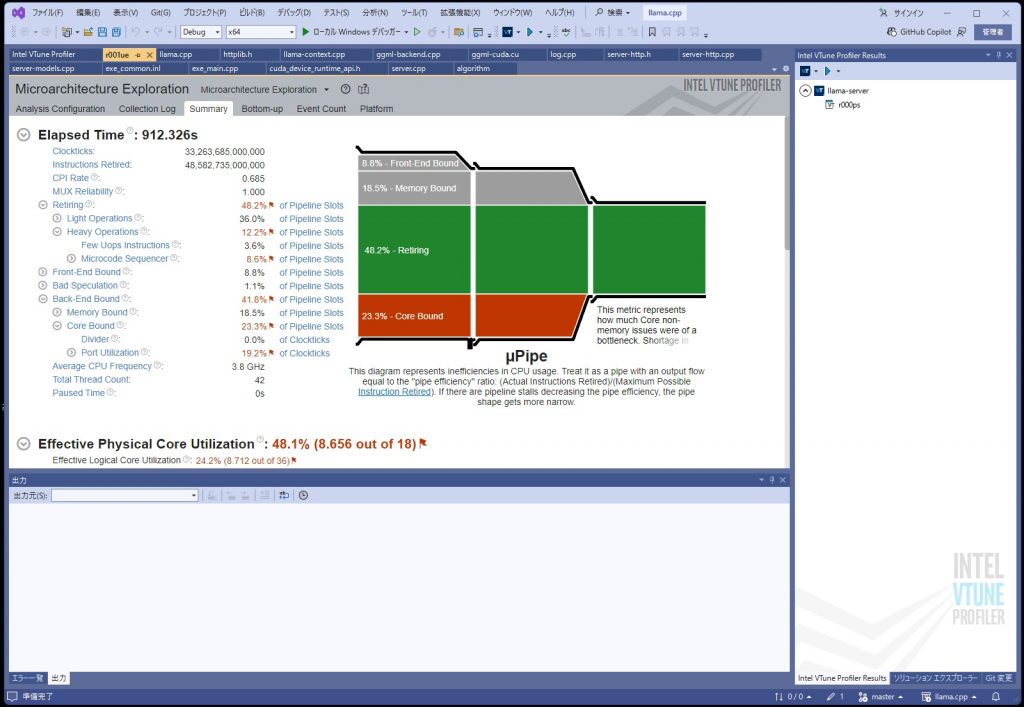
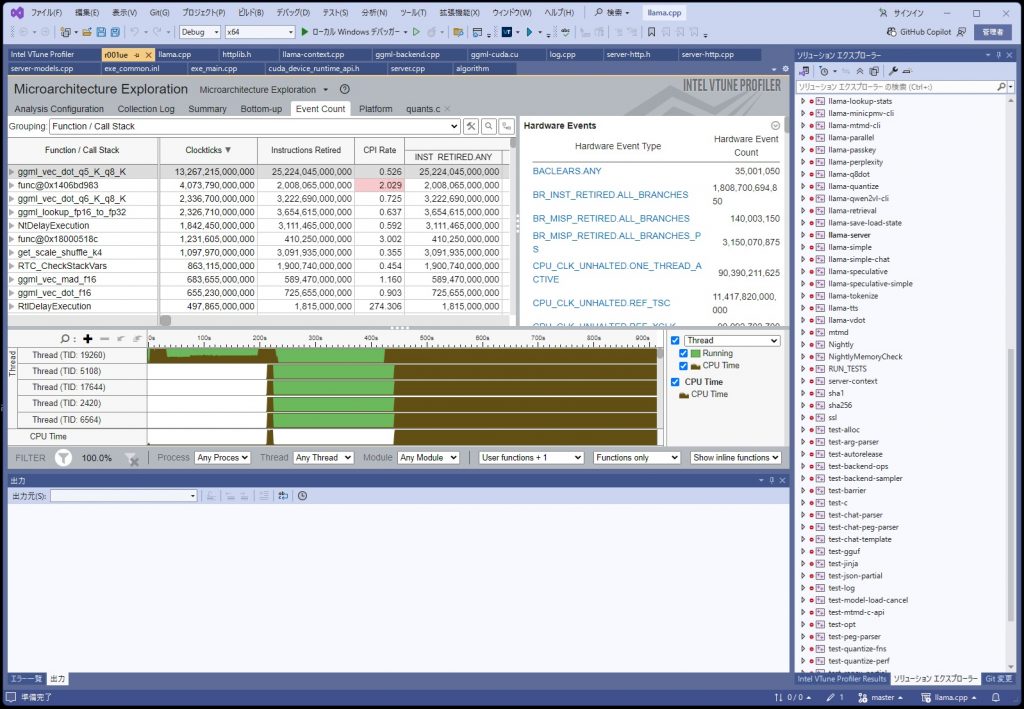
目的の箇所にたどり着けたのでよいが、途中、Bottom-upタブの見方が良く分からないので学習する必要がある。
最も時間がかかっている個所が判明したが、
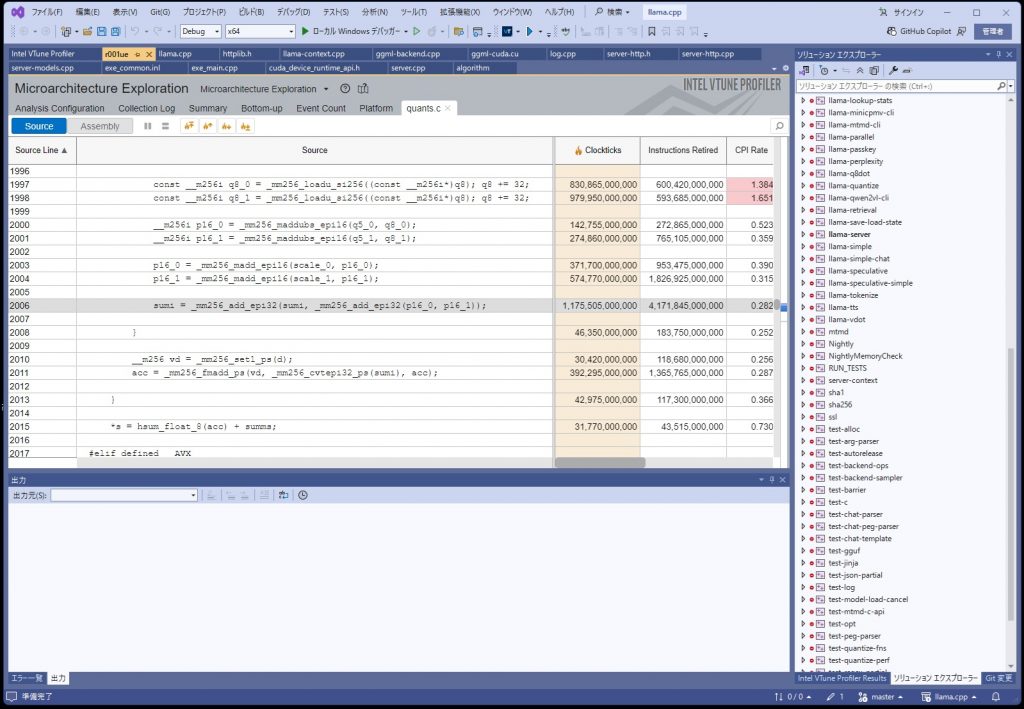
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_0, p16_1));
どうも、AVX2のコードのようである。まずは、AVX512で動かすにようにして、最適化をかけるようにする。
ボトルネックについて
パット見た感じなので確定的ではないですが、ボトルネックになっているコードは、モデルの重みデータを戻す処理のようである。このモデルデータは、重みが5ビットのものを使っているので内部で8ビットにしているようです。
llama.cppはAVX512を使うといっているがこのデータを戻すところはAVX2のままのようです。
考えてみれば当たり前といえば当たり前なのですが、なんとなく5ビットに圧縮したら展開するのに時間がかかるのではないかと思っていたら、その通りのようでした。この部分の処理時間は全体の約70%ぐらいを占めており、この部分を最適化することは期待がもてる。
もっとも、RAMを大量に積んで利用するモデルを8ビットとかにすればこの部分の処理をカットすることが出来るのでかなり早くなるかと思うが、メモリはこれ以上は積めないので最適化を頑張ろうかと思う。
変数は「箱」か「名札」か?― 初心者教育から束縛モデルまでを考える
以前、「変数は箱か名札か?」で動画を上げたのですが、あまりアクセスはなかったのですが、最近少しアクセスがあり、改めて見たら面白かったので、もう少し突っ込んでまとめてみました。
プログラミング教育の現場では、今も昔も「変数とは何か?」が最初のハードルです。
伝統的には「変数は値を入れる箱」と説明されますが、
最近では「変数はオブジェクトに貼られた名札(ラベル)だ」と主張する声も聞かれます。
一見、単なる比喩の違いのように見えますが、
この議論の背後には、プログラミング言語の理論と設計思想の根深い違いがあります。
ここでは、初心者教育から理論的背景、そして実用上の含意までを整理してみます。
Ⅰ. 初心者教育での「箱」モデルの意義
最初に登場するのが、もっとも直感的な「箱」モデルです。
変数とは、値を入れておく箱である。
a = 1
b = a
a = 2
このとき、a の中身を 2 に変えると、b の値はそのまま 1。
学習者は「箱に入れた値を取り出して使う」イメージで簡単に理解できます。
C や C++ のように、メモリ上の領域が実際に割り当てられる言語では、
この比喩はきわめて正確であり、教育的にも有効です。
Ⅱ. 「名札」モデルの登場と混乱
一方で、Python や JavaScript では、変数の実体がやや異なります。
これらの言語では、変数はオブジェクトへの参照を持つ仕組みであり、
代入は「名札を貼り替える」動作に近いのです。
変数は、オブジェクトに貼る名札である。
a = [1, 2, 3]
b = a
a[0] = 9
ここで b を出力すると [9, 2, 3]。
箱モデルでは説明しづらく、「名札モデル」の方が合うように見えます。
しかし、注意すべきはこの比喩も完全ではないという点です。
配列の各要素 a[0] にまで「名札」を持ち込むと、
今度は配列の連続性やメモリ構造のイメージが崩れてしまいます。
結果として、初心者をさらに混乱させることもあるのです。
Ⅲ. C/C++が示す「共存モデル」
C や C++ では、値型と参照型(ポインタ型)が共存しています。
int a = 1;
int &r = a;
このとき r は a の別名であり、どちらを変更しても同じ領域が変化します。
つまり C++ は、「箱」と「名札」の両方の性質を明示的に区別できる言語です。
教育的にはこの構造が非常に有益で、
物理的なメモリ構造と論理的な参照概念の橋渡しを学ぶことができます。
ただし、ポインタや参照はプログラミングの初心者にとっては難しい概念である。
Ⅳ. 関数型言語における「束縛モデル」
さらに理論的な世界へ進むと、
「変数は値を入れるものではなく、“値(あるいは式)に束縛される名前”だ」
という考え方が登場します。
束縛(binding)=変数と式の対応を定めること。
Haskell などの関数型言語では再代入ができず、
変数は一度束縛されたら変更できません。
x = 1
y = x + 2
このとき x や y は「箱」ではなく「式の定義名」です。
評価は遅延的に行われ、必要になるまで実際の値が求められません。
この仕組みは理論的には非常に美しく、
純粋関数・副作用の排除・数学的推論のしやすさといった利点をもたらします。
Ⅴ. 束縛モデルの強みと限界
束縛モデルの最大の利点は、式そのものをオブジェクトとして扱える点です。
たとえば、自動微分やDSL(ドメイン固有言語)の分野では、
式構造を保持して解析・変換する必要があります。
しかしその一方で、束縛モデルには現実的な制約もあります。
| 項目 | 束縛モデル(遅延評価) | 参照モデル(即時評価) |
|---|---|---|
| 抽象性 | 高い | 低いが直感的 |
| 実装効率 | 低い(オーバーヘッドあり) | 高い |
| デバッグ | 難しい(評価タイミング不明) | 容易 |
| メモリ予測 | 困難 | 明確 |
結果として、実用言語の多くは参照モデルを基本にし、
必要な箇所だけ束縛的な振る舞いを導入する設計を採用しています。
Ⅵ. 束縛モデルが主流にならなかった理由
-
- パフォーマンスとメモリ効率の問題
遅延評価や式構造の保持にはコストがかかる。
- パフォーマンスとメモリ効率の問題
-
- 最適化の困難さ
コンパイラが静的解析しにくく、最適化しづらい。
- 最適化の困難さ
-
- デバッグや可視化が難しい
どの時点で評価されたかが分かりづらい。
- デバッグや可視化が難しい
-
- 実際に必要なケースが限られている
自動微分やDSLなど一部領域に限定される。
- 実際に必要なケースが限られている
Ⅶ. 現代的アプローチ:必要な部分だけ「束縛的」に
今日では、C# の Expression<T> や
Python の sympy / jax、
C++ の Expression Template など、
必要な箇所だけ束縛モデル的挙動を模倣する仕組みが採用されています。
つまり、
「束縛モデル全体を採用するのではなく、
その一部を道具として使う」
という方向に落ち着いています。
Ⅷ. 教育的まとめ:段階的理解のすすめ
| 学習段階 | 目標 | モデル | 教育上の重点 |
|---|---|---|---|
| 初級 | 値の代入と操作の直感的理解 | 箱モデル | シンプルな心象で理解する |
| プロ(中級) | メモリと参照の関係を理解 | 箱+参照モデル | オブジェクト共有・ポインタ・参照 |
| 研究レベル | 抽象的な束縛・遅延評価・純粋関数 | 束縛モデル | 数理的抽象化・関数をデータとして扱う |
Ⅸ. 結論:「名札」は“箱”を超えるものではない
「名札」や「束縛」という比喩は、
実行環境や抽象化の観点を説明する一つの手段に過ぎません。
しかし、それを「箱より優れている」と主張するのは誤りです。
比喩はあくまで教育のためのツールであり、
言語設計の本質はメモリ・参照・評価戦略の選択にあります。
実務的な観点から見れば、
「箱モデル+参照の理解」で十分に事足り、
束縛モデルは特定分野での理論的・実験的意義を持つに留まります。
最後に:比喩の目的を取り違えない
変数を「箱」と呼ぶのも、「名札」と呼ぶのも、
プログラミングという抽象世界を理解するための足がかりに過ぎません。
重要なのは「どの比喩を使うか」ではなく、
その比喩がどの抽象化層を説明しているのかを意識することです。
プログラミング教育において本当に求められるのは、
比喩をめぐる正しさの議論ではなく、
学習者が言語の階層構造(値 → 参照 → 束縛)を自然に昇っていけるように導くこと
なのかもしれません。
この文章は、ChatGPTとの共同作業により作られています。
マルチスレッド&アセンブラプログラミングをしてみる(コラッツ予想のプログラム)
多コアCPUのコアを使い切るにはどうするか?とここ数年考えていたのですが、そういえばコラッツ予想(3n+1問題)を確認するプログラムはちょうどよい例だと思いプログラムを作成してみました。
CollatzAsmについて
せっかくなので64ビットアセンブラで作成し、128ビット(2の128乗)までの数を扱えるようにしました。ちなみに64ビットだと入力が数百億程度(35ビット程度)で内部の計算が桁あふれを起こします。
Visual Studio 2022(C++/Asm)で作成しています。ここからプロジェクトファイル一式をダウンロードできます。
Visual C++ですが32ビットバージョンはインラインアセンブラが使えるので、お手軽にアセンブラを使えたのですが、64ビットになりなぜかインラインアセンブラをサポートしなくなりました。ということで約30年ぶりにアセンブラのソースコードを書きました。
ちなみに、16ビット時代はアセンブラプログラミングの参考書が豊富にあったのですが、64ビットになりあまり見当たらなくなりました。昔はミックスドランゲージといって、Cからアセンブラを呼び出す方法もよく解説をされていたのですが、今では、ここに資料があるくらいで、基本的なことが分かっている人じゃないと意味不明かと思われます。
詳しい解説はご希望があればやりますが、このプロジェクトをサンプルとしてもらえればと思います。
また、このサンプルはC++14のマルチスレッドのサンプルにもなっています。長い間マルチスレッドプログラムと言えばOSのAPIかランタイム関数を使って作っていたのですが、C++14からプログラミング言語にサポートされたということで作成してみました。
実行例は以下のとおりとなります。
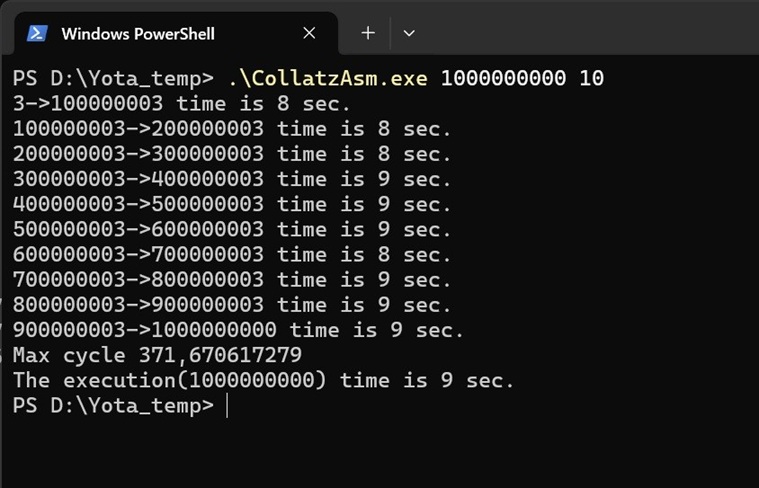
最初の引数で何処までの数を確認するかを入れ、2つ目の数は並列度(スレッド数)になります。
サンプルでは10になっていますが、当然コア数以上の値をいれます。32論理コアに対して100とかにしてもパフォーマンスが上がります(後述)。
CollatzAsmBenchについて
アセンブラでのプログラミングに限った話ではないのですが、プログラムの最適化の過程で試行錯誤を行うことがあります。特にアセンブラでプログラムすると様々な命令を使うことができるのでそのバリエーションが増えるかと思います。
ということで試行錯誤の記録として10個程アセンブラのコードのパフォーマンスを比較するプログラムを書いてみました。
以下、実行結果になります。
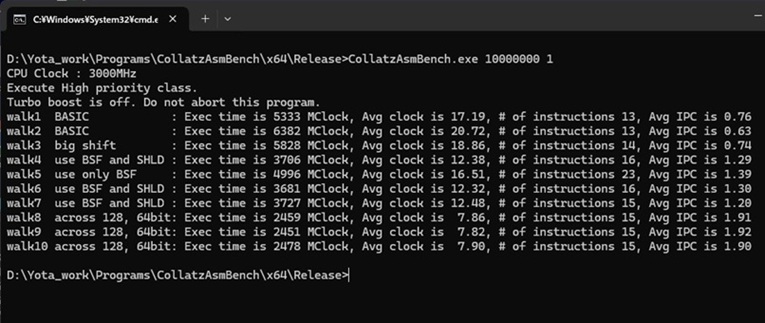
ChatGPTの出力コードとの比較
いわゆるバイブコーディングということで専用のツールも出てきていますが、コラッツ問題を扱うプログラムに関していうと、どこにでもあるのでChatGPTでも簡単なプロンプトでかなりいい感じのコードを出力しています。ということでChatGPTでプログラムを出力させてみました。、実際に試してみたところ可能でしたがあまり速度が変わらなかったので、今回はアセンブラでの出力はしていません。ChatGPTが作成したマルチスレッドのものを掲載します。
私が作ったコードと比較するとマルチスレッドの初期化の取り扱いがうまいです(emplace_backを使っている)。一方で、データ長は64ビット止まりで、並列性も論理コア数に従ってスレッドを作成していますが(hardware_concurrencyメソッドを呼んでコア数を取得している)、このプログラムの場合、各スレッドの実行時間が必ずしも同じではないので、スレッド数をより多くして各スレッドのタスクを細かくした方が、実行時間のばらつきの減少が期待できます。一方で、一般論になるのですが、論理コア数以上のスレッドを実行させると各スレッドがCPUのリソースを食い合いすることになるので、実行スレッド数を論理コア数に合わせるのも一つの手になります。
今回はアセンブラでは比較をしませんでしたが、CやC++のコードを単純にアセンブラにしてもあまり早くならないということもあります。一方で128ビットのような桁数の多い計算をさせる場合、アセンブラには桁あふれを処理する命令があり、CやC++で組むよりはるかに効率的なプログラムが記述できます。機会があればChatGPTでアセンブラプログラムの最適化を行いたいですが、↑の例にあるようにAIに任せるより、自分で工夫をした方が手っ取り早い面があります。もちろんですがアイデア出しをAIに頼ることもできますので、こういうことではあまりAIと人間の比較は意味がない(人間からしたらAIも利用する)ということになりますが、2025年9月現在、このあたりのチューニングはまだ人間の方に一日の長があるかと思います。(追記)この記事の公開後、1週間でClaudebotと名乗るロボットからZipファイルがダウンロードされたのでひょっとしたらClaudeにコードがパクられるかもしれません。
最後に実行結果を
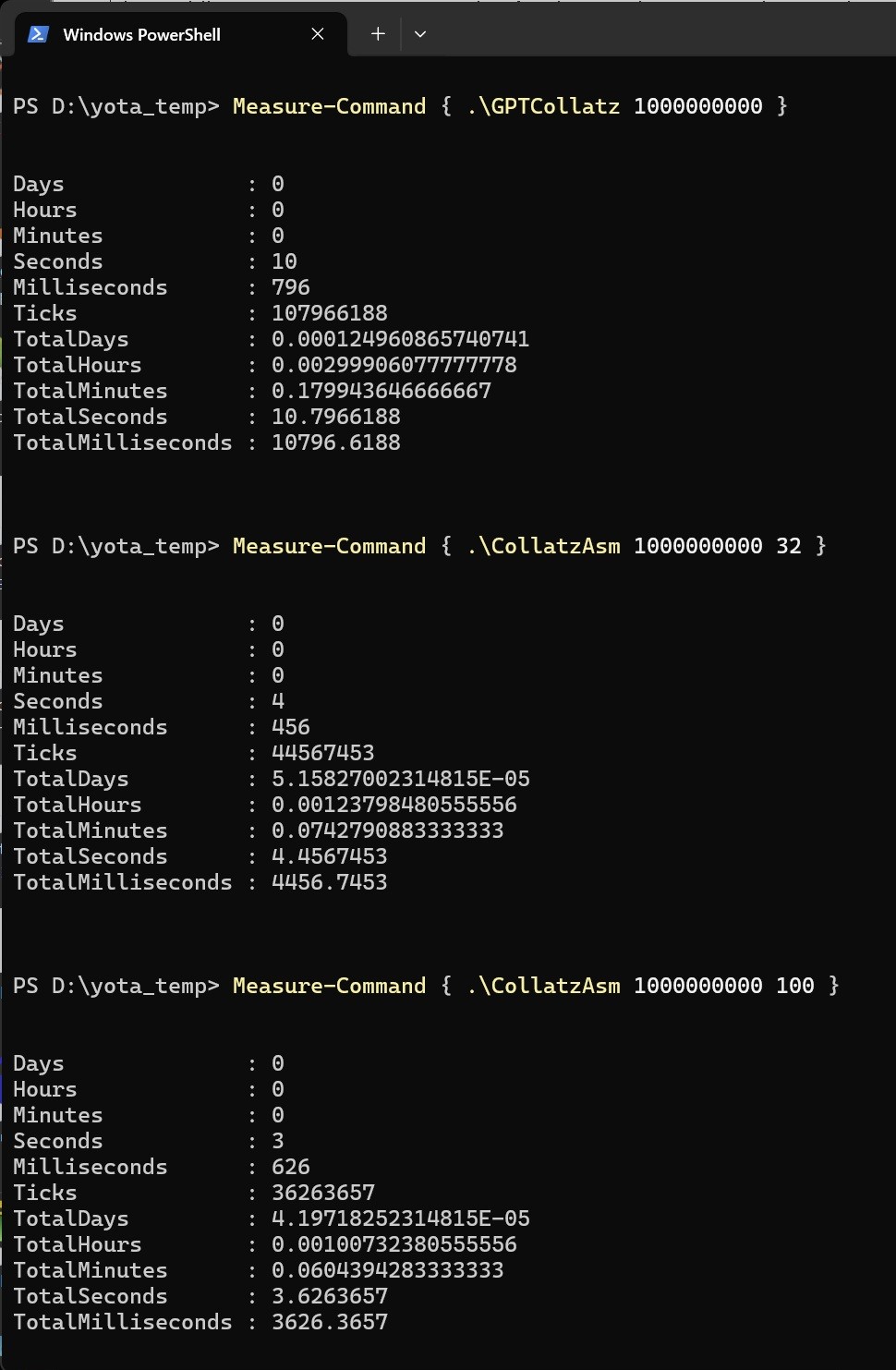
ということで、倍以上のパフォーマンスを示しています。逆にいうと倍程度にしかならないのですが、ある処理時間が半分になるということは2020年代のCPUの進化でいうとほぼ10年に相当します(この場合シングルスレッド性能の比較になる)。つまり上手くアセンブラでプログラムを書き直すことができればCPUの進化を10年先取りできるとも言えます。CPUのシングルスレッド性能の向上が顕著だった90年代ですと概ね1,2年でパフォーマンスが倍になっていました。
余談ですが、アセンブラでのプログラミングは8ビットや16ビットの時代は割と一般的でした。90年代以降ではCPU自体の進化が早かった為、アセンブラでのプログラミングがエンコードなど、いわゆるSIMD命令を使うためとか、ニッチになった感がありました。CPUのシングルスレッド性の向上が見込めなくなった昨今、アセンブラでのプログラミングが見直されるかもしれません。
話を戻すと、コラッツ予想の確認プログラムの場合、スレッド数を100にしても性能が伸びていることを確認できます。これは、前述のとおり値により処理ステップにばらつきがあるためで、区間を細かくした方が(スレッド数を多くし多方が)、CPUから見た場合のトータル処理時間が平均化される為です。
Visual C++ 2022 でも regex の multiline はサポートしない
時が流れるのも早いもので、ADPの開発に使用しているコンパイラをVisual Studio 2012 に変えてから10年が経とうとしています。途中、一度Visual Studio 2017 C++を試したのですが、regex がboostのモノと挙動が違うらしく($を行末とするにはmultilineサポートが必要とのこと)、この時はVisual Studio 2012に戻した。
最近、OSをWindows 11に変えて、『いい加減コンパイラも変えるか』ということで、Visual Studio 2022 の C++に変えました。
ちなみにVisual Studio 2012 は Professional を購入しましたが、Visual Studio 2022 は Community版 をインストールしました。
まぁ仕事で使うようになったら Professional を購入します。
Visual Studio は 2003、2008、2012と一つ飛ばしで買っていましたが(2012は不本意ながら、2008がWindows8で動かなかったから買った記憶があります)、その後、Visual Studioを使うのも ADP と SQL Server 2012 の開発用となったので、特にバージョンアップをしないで、だらだらとしていたら気が付けば、2013、2015、2017、2019、と結構なスキップとなりました。
気が付けば、Gitに対応していたり、なかなかの変わりっぷりですが、C++の開発関係はあまり変わらずでよかったです。
もっとも、C++言語の方が、C++11、C++14、C++17、C++20 と今迄の停滞はなんだったんだというぐらいに変わっているので如何したものかと思う。
一部、最適化に関わる部分(右辺値参照とか)があるので無視するわけにはいかず、コード自体は今後、変えていこうかと思います。
ちなみに長く止まっていた、C言語の方もC11やらC17やらに対応しているらしく(単にプロジェクトのプロパティを見ただけ)、C言語に徐々に書き換えるのもありかと思う今日この頃です(現実的ではないですが)。
新しい規格への対応で、1点、期待していたものが regex がありました。ADPは boostライブラリの regex を使っていたのですが、そのregex がC++11から規格に入り C++17 ではmultilineをサポートしたものになっていました。あくまでも個人的な趣味もありますが、私的には $ を行末としたいのですが、それまでのC++ の 標準regexは$はあくまでも文字列の最後という扱いでした。multilineで$が行末とみなしてくれるようになります。
ということで、さっそく試してみたのですが、VC 2022 ではどうも、multilineに対応していないようでした。
「なんでやねん」ということで、色々検索してみましたが、以下、Microsoft のDeveloper Communityの投稿を見つけました。
multiline [C++]
同じようなことを感じた人が投稿したらしいのですが、Visual C++の開発者と思われる方のコメントで、要約すると『規格制定で色々あったのですが、現在のところABIの破壊がないようにするために、このような実装となっています。回避策として引き続きBoostのRegexを使ってください、その方が挙動が一貫しているだけでなくパフォーマンスも良いです(意訳)』とのことです。
BoostのセットアップがVisual C++の環境では面倒なのですが、Boostも一緒にバージョンアップし(1.45 → 1.80)Visual C++ 2022の環境に移行しました。ちなみにコンパイラを変えただけではパフォーマンスが変わることは特になかったです(AVX等の命令を使うように変えればまた違うかもしれませんが・・・)。
RYZEN
2020年もすっかり明けて2月になりましたが、年明けに10年ぶりにPCを更新しました。ちょうど10年ほど前に、購入するPCの世代を統一しようと初代Core i7でソケット1366に決めたのですが、そこからCore i7-980Xを3つ程とi7-920を入手し4台のPCがあるわけですが、その後継ということでZEN2世代のRYZENに決めました。
Core i7を買ったときはちょうどWindows7に乗り換えた時でそこから8,10ときて、ここ2,3年は自分のPCがもっさりしていてグラフィックカードを変えたりしていましたがやっとこさ全とっかえができました。
今回はインテルからAMDに乗り換えたのですが、長いPC歴でちょこちょこAMDを使っています。今までメインマシンで使ったCPUを思い出すだけ書き出すと、こんな感じになります。
1984 (不明)ポケコンPB110
1985 uPD780(Z-80相当品) NEC
1989 80286相当品 AMD
1989 V30 NEC
1992 i486SX(J) Intel
1994 Am486 SX2-66 AMD
1996 Pentium 133 Intel
1997 MMX Pentium 166 Intel
1998 K6 AMD
1998 K6-2 AMD
1998 M2 Cyrix
1999 K6-III AMD
2000 Pentium III 600 Intel
2000 Pentium III 1000 Intel
2002 Celeron 1.4(PentiumIII系) Intel
2003 Celeron 2.3(Northwood-128K) Intel
2003 Pentium4(Northwood) Intel
2004 Athlon 64 3000+ AMD
2006 Pentium D 805 Intel
2006 Core 2 DUO E6400 Intel
2008 Xeon X3350(Core 2 Quad) Intel
2009 Core i7 - 920 Intel
2010 Core i7 - 980X Intel
2020 RYZEN9 3950X AMD
年号は大体ということで割といい加減です。その時の懐事情と趣味とその他諸事情で買い集めたり絞ったりしていましたが、こうしてみると2010年代のスキップぶりが半端ないですね。Core i7についてはSandy Bridge世代でそろえればよかったと少し後悔して、AMDからZenマイクロアーキテクチャが出る噂を聞きつけたときに様子見をしてZen2になったところで「行こう!」となった感じです。
話は戻って、初めての16ビット、32ビット、64ビットCPUは、AMDになります。初めての16ビットパソコンはPC-9801RXでしばらくはIntelを使っていると思っていたのですがあるときに中を開けてみたらAMDのCPUでした。よくよくカタログをみたら80286相当品と書かれていてものすごくがっかりした記憶があります。初めての32ビットCPUは、i486SX(J)と思いきや、このCPUは外部バス16ビットで、それを初めて知った時のがっかり感は半端なかったです。そのあとに買ったパソコンが今はなきコンパックのPresario CDS 524でこちらもメモリの増設で筐体を開けた時にみたらAMDでまたもやがっかりした記憶があります。その後、懐事情が改善し自作に移行して狂ったように買いましたが、初めてのDual-processor, Dual-core, Quad-core, Hexa-core はIntelになります。
RYZEN9は、初めての16-core(書き方を探すのが面倒)、PCI-E Ver4.0(Ver3.0はスキップ)、DDR4-RAM、UEFIです。利用面からは、初めてのCPUプロファイラ(AMDuProf)を使うプロセッサになります。CPUはキャッシュミスとか分岐予測ミスとかが発生すると内部のカウンタで記録をとるのですが、それを読み出すソフトウェアがCPUプロファイラということになります。有名どころではIntelのVTuneがあるのですがこのソフトがめっぽう高くCPUと合わせての購入となると個人では手が出しにくいです。AMDの方はなんと無料ということでまぁAMDということになりました。
そんなものを何に使うのか?と言われそうですが、もちろんADPのインタプリタ部分で、当初はVisualStudio付属のプロファイラを使って最適化を行っていましたが、いろいろ私に合わず、『V-Tuneかー』と思っていたところへ、CodeXL(AMDuProfの前身)の存在を知り、CodeXLに乗り換えたのが5年ほど前になります。CPUがIntelの場合、プロファイラは命令毎にかかった時間が分かるのですが具体的な原因(キャッシュミスなのか?ブランチペナルティか?とか)までは分からずそのあたりは手探りになっておったのがこれでばっちりと分かるようになります。早速プロファイルをしてみると、
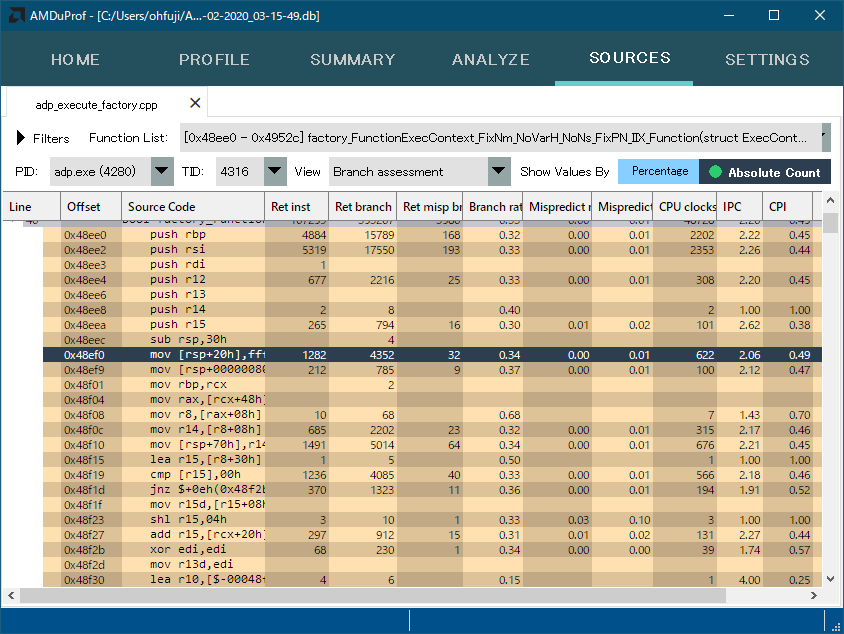
パットと見てよくわからない指標があるのでカウンタの意味についてはお勉強が必要なようです。例えばハイライト部分はただの代入になるのですが、それでなぜRet branchとかが関係するのか?(おそらく他のブランチとの関係で結果的に実行された/なかったとか言いたいのかもしれないのですが・・・)とか直接的でないところがあります。
ここにきて、ADPの実行ファイルサイズは約1MBになりますが、今まではプログラムやデータのメモリへの配置はコンパイラに任せていましたがそろそろそういったところまでも手を出す必要があるのかなと思っています。といっても具体的にどうするのか?という話ですが、先ずCPUプロファイラを使いながら基礎データを集めてその上でソースコードを再編集したり、インタプリタ本体を抜き出してミニマムなプログラムを作ってプロファイルをかけたりいろいろ実験ができそうです。
ちなみにこういった話をすると『じゃアセンブラで組めや!』と言われかねないのですが、まぁうざい煽りに真面目に答えると、要は今のプログラムはCPUの潜在能力を十分に生かし切れていないので工夫の余地があり、上手くいけば数倍早いプログラムが作れるということになり、2020年現在ではシングルスレッド性能で数倍といえば時間軸に置き換えると10年以上先に行けるという話になります。
どういうことかと言いますと、例えば1989年に出たi486DX(33MHz)と2000年に出たPentiumIII(1GHz)の性能比は、単純にクロック周波数で見ても30倍(実際はそれ以上)になります。次いで2010年に出たCore i7-980X(3.33GHz、ブースト3.6GHz)とPentiumIII(1GHz)との性能比は、クロック周波数でみて約3.3-3.6倍と伸び率が10分の1程度に減速しています。そして今回のRYZEN9 3950X(3.5GHZブースト4.7GHZ)とCorei7-980Xはクロック周波数ではブースト時で比較して1.3倍、実際に手元にあるADPのプログラムを動かしてみると整数演算で2倍となっています。つまり、それまでは最新のCPUと言えば以前のCPUより格段に速くなって10年も経てば桁違いの速さを見せたのですが2000年代の中盤頃からそのスピードが止まり、今では10年で2倍のパフォーマンスアップに留まることになります。
つまり今まではプアなプログラムを組んでも時間が経てば解決してくれるのですが、これからはきちんと考えて作らないとダメということになります。
CPUプロファイルの話はこの辺にしておいて、今回もう一つ試したいことがあるのが、仮想マシンの活用で今回、私が使う必要のあるプログラムの一部(eTaxとか弥生会計とか)を仮想マシンの方へ移しました。今までは再セットアップとなるとこれらのソフトを再インストールしなければならなくなり面倒なだけなのですが、それが不要となり気軽に再セットアップができるようになるので便利です。欠点としてはOSやらその他のライセンスがインストールするマシンの台数分必要になることと、RYZEN9 3950X特有かもしれませんがCPUプロファイルとの共存ができない(切替にUEFIレベルで設定変更が必要になる)ことでCPUプロファイルを取りたいときはいちいちマシンを再起動することになります。