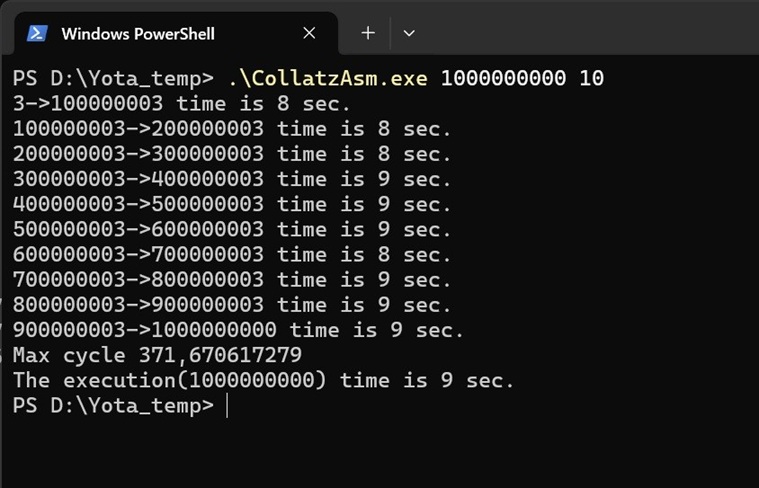
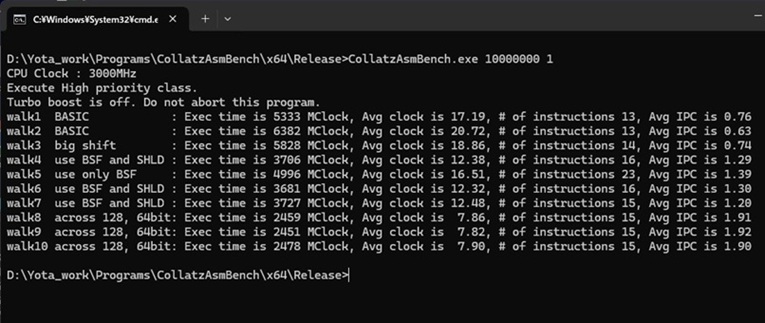
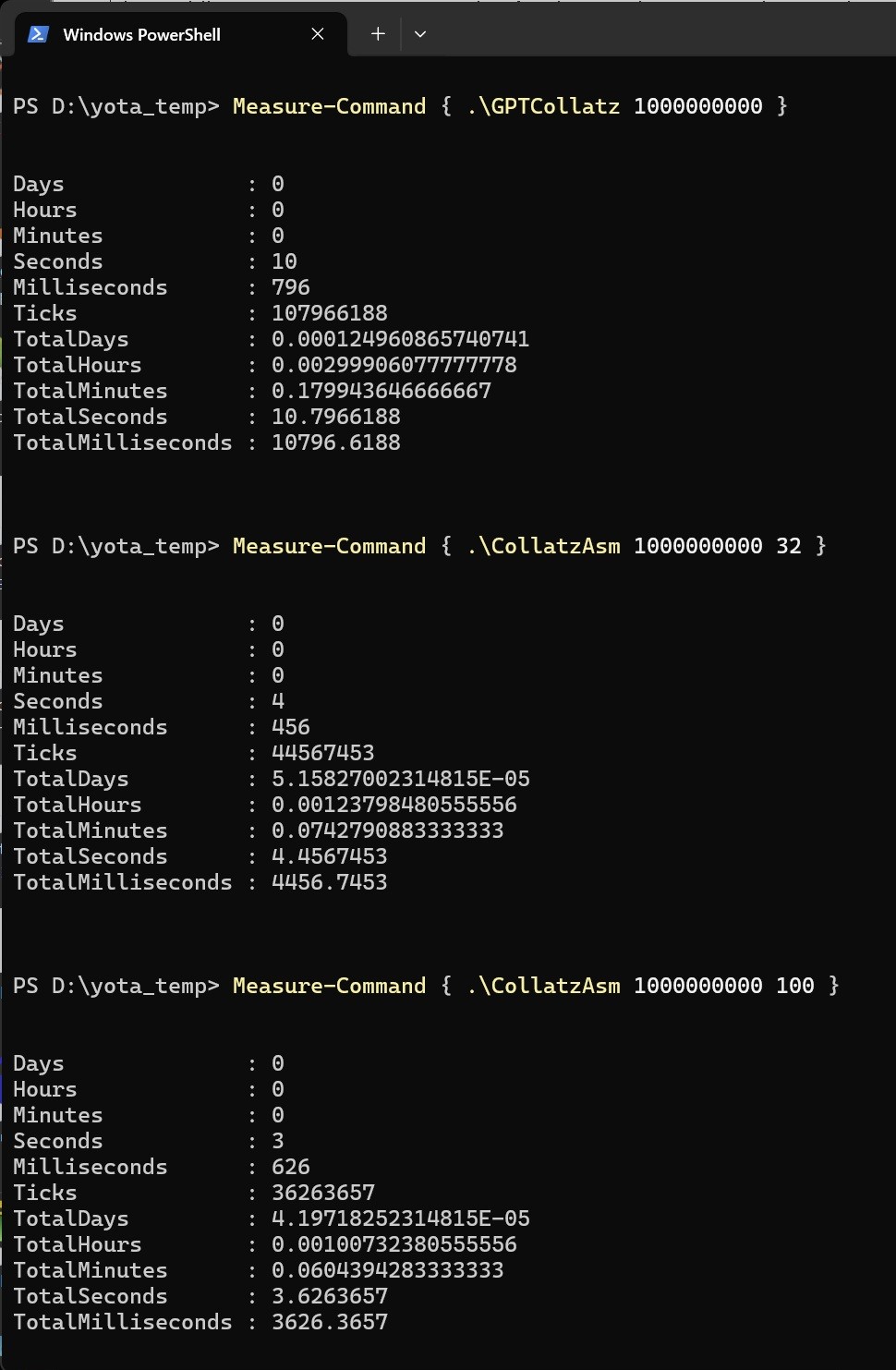
以前、「変数は箱か名札か?」で動画を上げたのですが、あまりアクセスはなかったのですが、最近少しアクセスがあり、改めて見たら面白かったので、もう少し突っ込んでまとめてみました。
プログラミング教育の現場では、今も昔も「変数とは何か?」が最初のハードルです。
伝統的には「変数は値を入れる箱」と説明されますが、
最近では「変数はオブジェクトに貼られた名札(ラベル)だ」と主張する声も聞かれます。
一見、単なる比喩の違いのように見えますが、
この議論の背後には、プログラミング言語の理論と設計思想の根深い違いがあります。
ここでは、初心者教育から理論的背景、そして実用上の含意までを整理してみます。
Ⅰ. 初心者教育での「箱」モデルの意義
最初に登場するのが、もっとも直感的な「箱」モデルです。
変数とは、値を入れておく箱である。
a = 1
b = a
a = 2
このとき、a の中身を 2 に変えると、b の値はそのまま 1。
学習者は「箱に入れた値を取り出して使う」イメージで簡単に理解できます。
C や C++ のように、メモリ上の領域が実際に割り当てられる言語では、
この比喩はきわめて正確であり、教育的にも有効です。
Ⅱ. 「名札」モデルの登場と混乱
一方で、Python や JavaScript では、変数の実体がやや異なります。
これらの言語では、変数はオブジェクトへの参照を持つ仕組みであり、
代入は「名札を貼り替える」動作に近いのです。
変数は、オブジェクトに貼る名札である。
a = [1, 2, 3]
b = a
a[0] = 9
ここで b を出力すると [9, 2, 3]。
箱モデルでは説明しづらく、「名札モデル」の方が合うように見えます。
しかし、注意すべきはこの比喩も完全ではないという点です。
配列の各要素 a[0] にまで「名札」を持ち込むと、
今度は配列の連続性やメモリ構造のイメージが崩れてしまいます。
結果として、初心者をさらに混乱させることもあるのです。
Ⅲ. C/C++が示す「共存モデル」
C や C++ では、値型と参照型(ポインタ型)が共存しています。
int a = 1;
int &r = a;
このとき r は a の別名であり、どちらを変更しても同じ領域が変化します。
つまり C++ は、「箱」と「名札」の両方の性質を明示的に区別できる言語です。
教育的にはこの構造が非常に有益で、
物理的なメモリ構造と論理的な参照概念の橋渡しを学ぶことができます。
ただし、ポインタや参照はプログラミングの初心者にとっては難しい概念である。
Ⅳ. 関数型言語における「束縛モデル」
さらに理論的な世界へ進むと、
「変数は値を入れるものではなく、“値(あるいは式)に束縛される名前”だ」
という考え方が登場します。
束縛(binding)=変数と式の対応を定めること。
Haskell などの関数型言語では再代入ができず、
変数は一度束縛されたら変更できません。
x = 1
y = x + 2
このとき x や y は「箱」ではなく「式の定義名」です。
評価は遅延的に行われ、必要になるまで実際の値が求められません。
この仕組みは理論的には非常に美しく、
純粋関数・副作用の排除・数学的推論のしやすさといった利点をもたらします。
Ⅴ. 束縛モデルの強みと限界
束縛モデルの最大の利点は、式そのものをオブジェクトとして扱える点です。
たとえば、自動微分やDSL(ドメイン固有言語)の分野では、
式構造を保持して解析・変換する必要があります。
しかしその一方で、束縛モデルには現実的な制約もあります。
| 項目 | 束縛モデル(遅延評価) | 参照モデル(即時評価) |
|---|---|---|
| 抽象性 | 高い | 低いが直感的 |
| 実装効率 | 低い(オーバーヘッドあり) | 高い |
| デバッグ | 難しい(評価タイミング不明) | 容易 |
| メモリ予測 | 困難 | 明確 |
結果として、実用言語の多くは参照モデルを基本にし、
必要な箇所だけ束縛的な振る舞いを導入する設計を採用しています。
Ⅵ. 束縛モデルが主流にならなかった理由
-
- パフォーマンスとメモリ効率の問題
遅延評価や式構造の保持にはコストがかかる。
- パフォーマンスとメモリ効率の問題
-
- 最適化の困難さ
コンパイラが静的解析しにくく、最適化しづらい。
- 最適化の困難さ
-
- デバッグや可視化が難しい
どの時点で評価されたかが分かりづらい。
- デバッグや可視化が難しい
-
- 実際に必要なケースが限られている
自動微分やDSLなど一部領域に限定される。
- 実際に必要なケースが限られている
Ⅶ. 現代的アプローチ:必要な部分だけ「束縛的」に
今日では、C# の Expression<T> や
Python の sympy / jax、
C++ の Expression Template など、
必要な箇所だけ束縛モデル的挙動を模倣する仕組みが採用されています。
つまり、
「束縛モデル全体を採用するのではなく、
その一部を道具として使う」
という方向に落ち着いています。
Ⅷ. 教育的まとめ:段階的理解のすすめ
| 学習段階 | 目標 | モデル | 教育上の重点 |
|---|---|---|---|
| 初級 | 値の代入と操作の直感的理解 | 箱モデル | シンプルな心象で理解する |
| プロ(中級) | メモリと参照の関係を理解 | 箱+参照モデル | オブジェクト共有・ポインタ・参照 |
| 研究レベル | 抽象的な束縛・遅延評価・純粋関数 | 束縛モデル | 数理的抽象化・関数をデータとして扱う |
Ⅸ. 結論:「名札」は“箱”を超えるものではない
「名札」や「束縛」という比喩は、
実行環境や抽象化の観点を説明する一つの手段に過ぎません。
しかし、それを「箱より優れている」と主張するのは誤りです。
比喩はあくまで教育のためのツールであり、
言語設計の本質はメモリ・参照・評価戦略の選択にあります。
実務的な観点から見れば、
「箱モデル+参照の理解」で十分に事足り、
束縛モデルは特定分野での理論的・実験的意義を持つに留まります。
最後に:比喩の目的を取り違えない
変数を「箱」と呼ぶのも、「名札」と呼ぶのも、
プログラミングという抽象世界を理解するための足がかりに過ぎません。
重要なのは「どの比喩を使うか」ではなく、
その比喩がどの抽象化層を説明しているのかを意識することです。
プログラミング教育において本当に求められるのは、
比喩をめぐる正しさの議論ではなく、
学習者が言語の階層構造(値 → 参照 → 束縛)を自然に昇っていけるように導くこと
なのかもしれません。
この文章は、ChatGPTとの共同作業により作られています。