JOINのパフォーマンスについての考察2(リレーションとの関係2)
ちょっと間があきましたが、JOINのパフォーマンス関連の続きになります。
前回、JOINのパフォーマンスについての考察(リレーションとの関係)でJOINを行った結果、データが非正規化するとその非正規化の度合いによってパフォーマンスが下がるという話をしました。
前回の記事では、1対nの結合ではJOINを外す(単純なSQLに分割してホスト言語側で結合させる)ということで、定性的な話しかしていませんでしたが、幾つか実験を通して、もう少し定量的な話をしてみます。
『たかがJOINで、なぜこねくり回すのか?』と思われるかもしれませんが、こういう実験&考察というのは意外に行われていないかと思います。私自身定性的なことは理解していたつもりでしたが、実際に実験を行うと色々と発見がありますので、記事にしてみます。
大切なことは解った気になることではなく真実を追究する姿勢で、先入観を持たずにきちんと実験を行いパフォーマンスに対する感性をみがくことは大切かと思います。
今回、調査するアルゴリズムについて
今まで何回か実験してきましたが、実験で使用してきたアルゴリズムについて説明します。1.SQLでJOINを行う。
SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price INNER JOIN Company ON (Price.CODE = Company.CODE)という風にSQLでJOINを行います。普通の処理になります。
2.ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)
1.のSQLを以下のように分割します。(1) SELECT CODE,RDATE,OPEN,CLOSE FROM Price (2) SELECT NAME FROM Company WHERE CODE = ?
(1)のSQLを実行して結果を取得しますが、NAMEについては(2)のように再度SQLを発行します。
ここで、単純にPriceテーブルの全ての行に対して(2)SQLを発行するのではなく同じ結果をキャッシュして同じCODEの場合はキャッシュからデータを取得するようにします。
3.ホスト言語側でJOINを行う(ハッシュJOINを行う)
1.のSQLを以下のように分割します。(1) SELECT CODE,NAME FROM Company (2) SELECT CODE,RDATE,OPEN,CLOSE FROM Price
(2)のPriceテーブルからのデータの取得に先立ちまして、(1)でComapnyテーブルから全てのデータを取得しておきます。
多くのDBMSで行っているハッシュ結合を真似ています。
1対nの2つのテーブルのJOINにおけるパフォーマンスモデル式
続いて、各アルゴリズムのパフォーマンス(実行時間)のモデル式を示します。ここで、
n : Priceテーブルの行数
m : Companyテーブルの行数
c10,c10,c20,c21,c22,c23,c30,c31,c32 : 比例定数
になります。
1.SQLでJOINを行う
1.のパフォーマンスのモデル式は以下のようになります。c11 * n + c10
Priceテーブルの行数に比例した時間で結果を取得できます。ここでc11は比例定数であり、C10はオーバーヘッドにあたります。
2. ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)
2.のパフォーマンスのモデル式は以下のようになります。c21 * n + c22 * m + c20
Priceテーブルの行数に比例した時間と、Companyテーブルの行数に比例した時間およびオーバーヘッドの合計になります。
『c22 * m は c22 * n * m になるのでは?』と思われるかと思いますが、キャッシュのおかげでこのようになります。
また、「1.SQLでJOINを行う」と比べますと、c22 * m と余計な項が付いていますので、
SQLでJOINした方が速い
と早合点される方がいらっしゃるかと思いますが、JOINのパフォーマンスについての考察(リレーションとの関係)で述べたことは、c11とc22の定数値の差異となって現れてきます。
3.ホスト言語側でJOINを行う(ハッシュJOINを行う)
3.のパフォーマンスのモデル式は以下のようになります。c31 * n + c32 * m + c30
面白いことですが、形式的には「2. ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)」と同じになります。
ちなみに、[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011 にあります、「SQLの発行回数のオーバヘッドはどこにいったんや?」と思われるかもしれませんが、それはc32とc22の差異に出てくるということになります。
実験と結果
今回の実験では、nの値を変えながら実行時間を計測することにより、各モデル式の定数を求めます。求めるといってもグラフを書いて状況を観測します。厳密には回帰分析とかを行うことになるでしょうが、グラフが直線になることと、nが増えたときの傾向をつかめればよろしいかと思います。アルゴリズムの教科書ではオーダーという概念があり、オーダーでは定数を求めることは無意味とされています。つまり上記のアルゴリズムは論理的には違いがなくどれも一緒ということになります。
つまり、2倍や3倍の差はあまり意味がないということですが、もっとも、実際の現場ではこのような差にも敏感になるので、きちんと計測して値を出すことになります。
また、今回はmは固定(約2000)で行っています。mが変動したときにどう変わるのかも興味深いですが今回は、m << n ということで結果にはあまり影響しません。
先ずは、結果から、
| 0行 | 373,740行 | 1,172,191行 | 2,002,749行 | 4,671,568行 | |
|---|---|---|---|---|---|
| 1.SQLでJOIN | 718 | 10,015 | 29,938 | 52,329 | 119,192 |
| 2.キャッシュ付のネステッドループJOINを行う | 671 | 10,469 | 30,172 | 49,814 | 116,770 |
| 3.ハッシュJOINを行う | 2,828 | 11,422 | 29,797 | 49,845 | 110,988 |
つづいて、グラフを以下に示します。
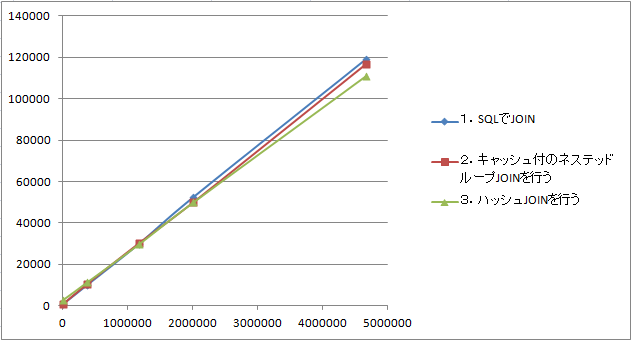
縦軸が時間で、横軸が行数(n)になります。グラフをみますとPriceテーブルの行数(n)が増えると「1.SQLでJOIN」より、「2.キャッシュ付のネステッドループJOINを行う」や「3.ハッシュJOINを行う」の方が速くなっていくことが解るかと思います。
パフォーマンスにシビアになる時は、往々にしてnの行数が増えるような場合にあたるということになります。その場合は1より2や3を選択した方がよいということになります。
もっともグラフを見て解るとおり差はあまりないので、通常はやはり普通にSQLでJOINを行い、パフォーマンスを稼ぎたくなったら2や3を検討するということになるでしょう。
2011-09-29 | コメント:0件
JOINのパフォーマンスについての考察(リレーションとの関係)
コメントを頂いたのですが、ちょっと返し方が悪かったのか音信普通になりましたので、改めてJOINのパフォーマンスについて考察してみます。1対n結合の場合、JOINとは正規化データから非正規化データを作り出す操作になる
RDBのテーブルは、きちんと設計されていれば、正規化されています。つまりデータに重複がなく容量の面で効率的になっています。ここで正規化データとはあくまでもRDBにとって効率的というだけでそれ以上のものではありません。一方で人間が理解しやすいデータ形式は必ずしも正規化データというわけではなく、往々にして非正規化されたデータの場合があります。JOINを行うということは正規化されたデータを非正規化データに戻す操作ということに相当します。つまり、効率のよいデータから人間にとって理解しやすいデータ形式に戻す操作になります。JOINは正規化されたデータから非正規化という効率の悪いデータ形式に変換する操作になります。
SQLでJOINを行い、その結果を取得するということは何らかの非効率な行為が行われているということがわかるかと思います。
RDBのコピーを行おうと考えた場合、わざわざJOINなどせずに、テーブル毎にコピーを行おうとするでしょう。RDBからデータを取り出すとき同様に正規化された単位でデータを取得した方が有利な場合があるということは理解できるかと思います。
RDBでは正規化データから非正規化データを作り出す方が非正規化データから正規化データを取り出すより効率的
先ほど、JOINは非効率といいましたが、なぜRDBでは効率の悪いJOINが行われるのでしょうか?理由は簡単で、RDBの理論では、
・非正規データ から 正規データ を作る
操作より
・正規データ から 非正規データ を作る
操作の方が効率的と考えられているからです。非正規データから正規データを得るにはグループ化を行います。つまりGROUP BYを行う必要がありますがこれはつまりソートを行った上に重複したデータを圧縮することに相当します。一方でJOINはデータの検索に相当します。例外はありますが検索の方がソート&圧縮より効率的なのは理解できるでしょう。
さらに、正規化データは非正規化データより更新が容易ということもあります。
つまり、関係データベースの世界では正規化されたデータは非正規化されたデータより効率がよいと考えられています。ちなみに、この認識が間違って拡大解釈され、『SQLは効率がよい』という誤解が生まれたと想像されます。
1対nの結合で一方のレコードサイズが小さいとき、2つのテーブル間の単純なJOINは効率的、だがデータの出力が非効率
FROM table_a INNOR JOIN table_b ON (table_a.table_b_ID = table_b.ID)のSQLがあるときに、
table_aがマスターを参照するテーブルで、table_bがマスターテーブルと仮定します。つまりtalbe_aとtable_bが1対nで結合されており、さらにtable_bがメモリに入る場合、JOIN自体のコストはほとんどかかりません。
2011年現在、サーバーに搭載されるメモリ容量が数十GBのオーダーになります。一方でマスターテーブルの容量は多く見積もっても数百万件のオーダーになり、各データを多く見積もって1KBとしてもマスターテーブルのデータ容量は数GBのオーダーとなります。実際にはJOINに必要なデータのみメモリにおいた場合、必要なデータは1桁も2桁も減ることになります。結果として1対nの結合ではほどんどの場合、マスターテーブル側はメモリに乗ることになり、JOINにおいてマスター表の操作は高速に行えます。
しかし、1対nの結合では、結果を取得する場合に、結果データが非正規になる為に非効率になります。
この場合、JOINを分割して、呼び出し言語側でJOINした方が理論的には効率的になります。実際どこまで効率的になるかは分割による複数回のSQLの呼び出しのオーバヘッドと繰り返しデータの量に左右されます。
1対1結合の場合は、JOINは出力も含めて効率的になる
1対1結合の場合は、結果データも正規化しているのでJOINは効率的になります。JOIN自体が効率的に行えるかどうかはデータ量やデータ(または結合キーのインデックス)が整列されているかどうかによります。結論
以上のように、扱うデータの性質によってSQLでJOINさせる方がよい場合とSQLではJOINさせない場合の方が理論的に速くなる例を示しました。結合の種類が1対nの場合、JOINを行うとデータ非正規化し、容量が増えるので出来るだけJOINを遅らせるテクニックが有効になる場合があります。
実際にどのような状況のときにJOINを遅らせたほうがよいかですが、マシンのスペック、ネットワークの環境等に依存しますが、傾向として行数が増えた場合や1対nのJOINの数が増えるとJOINを遅らせる方が有利になります。このような場合でパフォーマンスに問題が発生した場合にJOINを遅らせるテクニックを検討されると上手くいく可能性が高まります。
一方で、結合の種類が1対1の場合、データは非正規化しないので、SQLの発行の段階でJOINを行えば有利になります(JOIN自体のコストはまた別の話になります)。
2011-09-06 | コメント:0件
[ADP開発日誌]0.74リリース マルチスレッド化の第一歩 & LLPlanets発表用リリース
ADP公開一周年記念記事がまだ途中ですが、 Ver0.74のリリースを行います。
Ver0.74は、Accessでの整数のインサート時のエラーの改修と、pipe述語の実装があります。
pipe述語というのは、以前話に出ました、マルチスレッド機能の1つでパイプライン処理を実現する述語になります。
ちなみに、本リリースにに基づき、LLPlanetsのライトニングトークで発表を行います。私を見かけた人は『ブログ見てます』と声を掛けていただければうれしかったりします。
では、pipe述語の使用例を見てみましょう。何回かやっていて最近ホットなSQLのパフォーマンスについての例になります。
関連記事1:[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
関連記事2:SQLの実行パフォーマンスについて 2010
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行(再掲)
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験1と同じです。
実行時間も同じで、約119秒です。
実験2 ADP側でjoin(ネステッドループ&キャッシュ)
続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験2-Bと同じコードになります。
実行時間ですが、約117秒となりました。実験1と比べて約1.6%程速くなっています。
実験3 ADP側でjoin(事前にマップ作成)
3つ目は、ADPでも事前にマップを作成し、joinを行うことができます。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験3と同じコードです。
実行時間ですが、約111秒で実験1より7%ほど速くなっていることが解ります。
続いて、pipe述語を使って並行処理をさせてみます。
実験1-P 素直にSQL側でjoinをさせたものをpipe実行
実験1のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).pipe.csv.prtn,next;
実験1のコードとの違いは4行目の,sql@($db,$str,[]).pipe.csv.prtn,next;
のpipeという記述で、これがpipe述語になります。pipe述語で区切られたコードは並行で処理を行います。
つまり
,sql@($db,$str,[])
の部分(バックトラックの実行)と
.csv.prtn,next;
の部分は並行で動作します。
sqlの部分は、.csv.prtn,nextの実行中にバックトラックを行います。
next述語で、pipeまで戻りますと、sqlの実行を待ち(同期)データを受け取ります。
ややこしいかも知れませんが、図で示すとよくわかるかと思います。
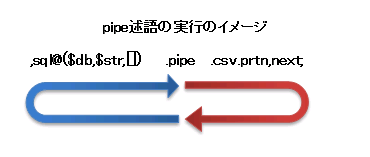
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。

比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験2-P ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行
続いて、実験2のコードにpipe述語を挿入しています。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
実行時間は、約89秒で実験2と比べて約24%速くなっています。
興味深いのは実験1-Pよりも速度向上が大きいです。pipe述語は半分に分割してそれぞれ実行するという方式をとっていますが、当然ですが常に半分になるとは限りません。上手く半分に分割できる場合もありますし、そうでない場合もあります。そのような関係でこのような逆転現象が発生します。一口にJOINのパフォーマンスといってもこのように様々な要因が絡んできますので、一概に『○○が効率的』といえないことを表す良い例となっています。
実験2-PP ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行2
実験2-Pのコードにさらにpipe述語を挿入しています。pipe述語は1つだけでなく複数入れることもできます。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,pipe ,csv($rec,$name).prtn,next;
実行時間は、約112秒で実験2-PPと比べて逆に遅くなっています。このように闇雲にマルチスレッドを行っても必ずしも速くならない場合がある(もちろん速くなる場合もある)のが面白いところです。pipe述語を2つ使うと3つスレッドが動作しますが、実験環境ではCPUコアが2つしかないので足の引っ張り合いのようなことになったようです。
実験3-P ADP側でjoin(事前にマップ作成)でpipe実行
続いて、実験3のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
実行時間は、約91秒で、実験3と比べて約18%速くなっています。
ちなみに実験3-Pからさらにpipeを挿入しても良いのですが、実験2-Pの時と同様にあまり速くならないので省略します。
結論
各実験結果を示します。
| 実験 | 実行時間(秒) |
|---|---|
| 実験1 | 119 |
| 実験2 | 117 |
| 実験3 | 111 |
| 実験1-P | 108 |
| 実験2-P | 89 |
| 実験2-PP | 112 |
| 実験3-P | 91 |
実験1~3どの場合でも、pipe述語が有効だということが分かります。これは、
・DBMSからデータを取得する
・ファイルへ書き出す
という2つのIO処理があり、pipe述語によって、それらを同時に実行することが出来る為です。
また実験2-PPと実験2-Pを比べても分かりますとおり闇雲にマルチスレッド化しても高速化が図れない場合もあります。
パフォーマンスアップは様々な要素が関わってきますので実験により確認しながらということが必要になります。
pipe述語はお手軽にマルチスレッドを実現でき、また取り外しも楽なので簡単に実験や試行錯誤が出来ます。
ADPのpipe述語はキャッシュ機能と同様に便利な道具として利用できるかと思います。
また、実験1-P、2-P、3-Pを比較しますとどれをとってもパフォーマンスにあまり差がないことがわかるでしょう。ADPの開発にあたりプログラマの自由度を高めるということも考慮しています。つまり、『○○でなければダメ』ではなく、どのアルゴリズムを採用するかはプログラマーの判断で、いか様にも選択できるような言語を目指しています。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
2011-08-19 | コメント:0件
OpenBlockS 600
Windows7,2008R2に引き続き、これまた1年越しの作業になりましたが、我がohfuji.nameをホストするマシンをOpenBlockS 600(正確にはOpenBlockS 600D相当)に置き換えました。OpenBlockS 600とは、ぷらっとホーム社さんが製造・販売しているマイクロサーバーで、こちらが製品情報になります。ちなみに2月現在キャンペーンをやっておられます。
OpenBlockS 600自体の解説はいろいろな場所で行われているので、そちらにおまかせしますが、特質すべきは、抜群の低消費電力で、私がエコワットで測定した結果は9Wでした。またファンレスでストレージはコンパクトフラッシュを使うので音が出なくてかつ障害に強く、商業利用はもちろん、自宅サーバーとしても重宝するかと思います。
OSですが、OpenBlockS 600はSSD Linuxがプリインストールされています。また600DはDebianがプリインストールされています。メモリは1GB積んでいますのでDNSサーバーやメールサーバーとしては申し分ないスペックです。
難点が、CPUにPOWER-PCを使用しているところで、私のようなプログラミングをする人間にとっては開発環境を別途用意しないといけないのと、さらにそのCPUの動作周波数が600MHzとお世辞にも速いと言えないところで、Apacheで静的なページを運用するならともかく動的なページは難があるかと思います。特に普通のサーバーでも重たいWordpressをOpenBlockS 600で運用するのは厳しいかと思います。
では、このブログ(Wordpressなんですが・・)はどうしているのかと言いますと、このページはADPで作成したブログビューアーで表示しています。我がADPもOpen BlockS 600Dに移植しまして、このとおり動作しておる次第です。このページを頻繁に訪問される方は気がついておられたかと思いますが、最近Wordpressが重くなっていたので、どげんかせんといかんと思っておったところです。このような厳しい条件を克服するのはソフトウェアエンジニアとしてロマンを感じたりします。
しばらく運用してみてOKであれば、OpenBlockS 600D版のADPと共にブログビューアー(Adp WorPdress bLOG viewer - AWPLOG)のソースを公開しようかと思っております。
2011/06/23 追記:節電の為、自宅サーバー類は仮想マシンとして別のサーバーに集約しましたので、現在このサーバーはOpenBlocks 600D上では動作していません。
2011-02-07 | コメント:0件
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
以前に書いたこの記事に関してコメントをもらいちょうど記事にしようかと思っていたところでしたので、ADPのキャッシュ機能を使い、この記事の実験をADPでやったらどうなるかみてみます。
SQLでjoin(結合)と言えばSQLに慣れた方にとっては馴染み深いものですが、初心者にとっては一種の登竜門のようで、joinを避けたコードを見かけたりすることがあります(まぁ私も十数年前にはこのような理由でjoinを避けたコードを書いた記憶があります)。また、O/Rマッパーではテーブル毎にクラスを対応させる関係で、joinの取扱がややこしかったりします。
それ以外でも、私の場合になりますが、過去にパフォーマンス上の理由からjoinを行わなかったことがあります。
今回は、前回の実験と同様に
・SQLでjoinさせる。
・ADPでjoinさせる。
でパフォーマンスの違いについていくつかの実験を行い計測します。
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
少しコードの説明を、
1行目の、$db=~ の部分は、ODBCの接続文字列を指定します。上記のコードは、ODBCのデータソース名Tradeを指定している接続文字列になっています。
2,3行目の、$strの部分はSQL文を変数$strに代入しています。本来は1行で書けますが、wordpressで見やすいように2行で書いています。
4行目の
,sql@($db,$str,[]).csv.prtn,next;
sqlは組み込みの述語で、「ODBC-APIを使いsqlを実行し、結果を配列(@)で受け取り、csvに変換し、prtnで画面に出力し、nextで全ての結果を出力する」というコードになります。
自画自賛になりますが、必要最低限の情報だけで簡単にSQLが発行できているので、ADPの開発目標の一つである「SQLとの親和性が高い言語を目指す」を具現している例だと思います。
実行時間ですが、
D:\>adp -t sql_test_1.p > sql_test1.txt time is 119192ms.
で、約119秒となりました。
実験2-A ADP側でjoin(ネステッドループ)
続いて、ADP側でネステッドループjoinさせてみましょう。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
ADPのDBライブラリは、前に紹介しましたODBCライブラリがベースになっていますので、ODBCのパラメータクエリが使えます。
5行目のコードがパラメータクエリを使っています。
実行時間ですが、
D:\>adp -t sql_test_2.p > sql_test2.txt time is 1717284ms.
で、約1717秒となりました。実験1と比べて約14倍の実行時間です。
実験2-B ADP側でjoin(ネステッドループ&キャッシュ)
さらに続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
呼び出し述語名の後ろに$をつければキャッシュ機能がONになります。上記のコードでは5行目の sql$ がキャッシュ機能を使用しています。
では、実行時間をみてみましょう。
D:\>adp -t sql_test_2.p > sql_test2.txt time is 116770ms.
で、約117秒となりました。
実験2-Aと比べるとかなり高速化がはかられたかと思います。キャッシュのこのような使い方は、かなり有効だとうことが解るかと思います。繰り返しになりますが、ADPならお手軽にキャッシュ機能を使うことができます。
実験3 ADP側でjoin(事前にマップ作成)
ちなみに、ADPでも事前にマップを作成し、joinを行うことができます。以下、コード例です。
,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
前回の記事ではC++でハッシュjoinを行うと書いたので『ハッシュJOINを言語で再開発するのは非効率』とコメントをもらいました。
コードを良く読んで頂ければ解るかと思いますが、実はC++の例でもjoin自体はプログラミング言語(ライブラリ)の機能を使っており、取り立てて複雑なことはしていません。
やっていることを説明しますと、マスターテーブル用のマップを事前に作成し、それを使ってjoinを行っています。慣れていない人にとっては難しいかもしれませんが、古くはperlの連想記憶、最近(これも古いが)の例ではVBScriptのディクショナリに相当します。DBMSを使わないで日常的にファイル処理を行っている方にとっては日常的なコードかと思います。
ちなみに、ADPのコード例ですが非常にすっきりとしているかと思います。C++の例と比べると本来やろうとしていることが明確になっているかと思います。
実行時間は、
D:\>adp -t sql_test_3.p > test3.txt time is 110988ms.
で、約111秒とやはり実験1より速くなっていることが解ります。
こうしてみると、実験2-Bが思いのほか速くなっていないと思わるでしょう。
これはSQLの実行回数に関係しています。
各実験のSQLの実行回数を見てみましょう。
| 実験1 | 1回 |
| 実験2-A | 約470万回(Priceテーブルの行数+1) |
| 実験2-B | 約2000回(Companyテーブルの行数+1) |
| 実験3 | 2回 |
になります。実験2のコードではテーブルの行数に比例した数だけSQLを実行することになります。実験2-Bが実験2-Aより速いのは、Priceテーブルの行数よりComapnyテーブルの行数が圧倒的に少ないから、つまり1対nの結合を行っているからで、仮に1対1の結合では速くならないということになります。
実験3がなぜ実験1より速いかですが、DBMS側から転送されるデータ量が違います。
以下、CSVファイルの先頭5行を表示します。
1717,2005-05-10 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-11 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-12 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-13 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-16 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
企業名の『明豊ファシリティワークス(株)』が重複して余分なデータとなっています。実験1のコードではDBMSから言語側にこのように重複したデータが来ます。各実験で転送されるデータ量を見てみましょう。
| 実験1 | 約256MB |
| 実験2-A | 約256MB |
| 実験2-B | 約184MB |
| 実験3 | 約184MB |
実は、DBMSから言語側へ転送されるデータ量自体は、実験1より実験2-Bの方が少なくなります。そのような関係で、実験1より実験2の方が早くなっています。SQLの実行回数(実験1の方がよい)とデータ転送量(実験2の方がよい)になりますが、このあたりはハードウェアの環境やDBMSによって結果が変わってくるでしょう。
この2つのデータから実験3は、なるべく少ないSQLの実行回数で少ないデータ量を転送しているということが解るかと思います。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
2011-02-01 | コメント:0件